ローカル環境でAIを動かしたい人にとって、Ollamaは、おすすめの実行環境です。
Mac・Windows・Linuxで使え、Web UI、CLI、REST APIまでそろっているため、初心者から開発者まで扱いやすいのが魅力です。
さらに現在は、Gemma 4をOllamaで利用でき、推論、コーディング、エージェント的な処理、画像理解まで幅広く試せます。
Ollamaとは
Ollamaは、LLM(大規模言語モデル)を自分のPC上でローカル実行できるツールです。
主な特徴は3つあります。まず、1行のコマンドだけでモデルを起動できるシンプルさ。
次に、ブラウザ上のチャット画面からすぐに使えるWeb UI。
そして、REST APIを通じてアプリやスクリプトから呼び出せる拡張性です。
すべての処理がPC内で完結するため、データをクラウドに送りたくない場面や、手元に検証環境を用意したいときに特に向いています。
Gemma 4とは
Gemma 4は、Google DeepMindが開発するGemmaファミリーのひとつで、テキストと画像を入力でき、テキストを出力するマルチモーダルモデルです。
Gemma 4には高い推論能力、可変アスペクト比や解像度に対応した画像処理、複数サイズの展開、ローカル実行に向く小型モデルなどの特徴があります。
Ollamaから配信されたGoogle Gemma 4の案内メールでも、Gemma 4は推論、エージェント的なワークフロー、コーディング、マルチモーダル理解に向くモデルとして紹介されています。
つまりGemma 4は、単なる会話モデルではなく、実務や開発の補助まで視野に入れたモデルとして位置づけられています。
Ollamaで使えるGemma 4のモデルサイズ
Ollama公式ページでは、Gemma 4は複数のサイズで公開されています。
主なタグは gemma4:e2b、gemma4:e4b、gemma4:26b、gemma4:31b、gemma4:31b-cloud です。
小型モデルは128Kコンテキスト、中型以上は256Kコンテキストに対応しており、いずれもText / Image入力に対応しています。
特に小型の gemma4:e2b は約7.2GB、gemma4:e4b は約9.6GBで、ローカルPCでも比較的試しやすいサイズです。
一方、gemma4:26b は約18GB、gemma4:31b は約20GBで、より大きな文脈を扱える256Kコンテキスト対応モデルとして掲載されています。
また、gemma4:31b-cloud も用意されており、Ollama公式ページではクラウド側の選択肢として紹介されています。
ローカルマシンの負荷を抑えつつ、より大きなGemma 4を使いたい人には注目しやすい構成です。
E2B・E4B・26B・31Bの違い
Ollama公式ページでは、E2BとE4Bの「E」はeffective parametersを意味し、エッジデバイス向けに作られたモデルと説明されています。
軽量でローカル実行しやすいモデルを探しているなら、まずはこの2つが候補になります。
一方、26Bと31Bはワークステーション向けモデルとして案内されています。
26BはMixture of Expertsで4B active parameters、31BはDenseモデルです。
より高い性能や長いコンテキストを求めるなら、こちらの系統を検討しやすいでしょう。
Gemma 4はどんな用途に向くのか
Gemma 4は推論、エージェント型ワークフロー、コーディング、マルチモーダル理解に向いています。
つまり、単純なチャットだけでなく、次のような用途と相性が良いといえます。
- 長文の要約や整理
- コード生成やコード補助
- ツール連携を含むエージェント的な処理
- 画像を見せながら説明させる使い方
さらに、Gemma 4はthinking modesを設定できる高性能なreasonerとしても使用できるため、単なる軽量モデル以上の役割が期待されています。
OllamaでGemma 4を使う
Ollamaそのものの導入方法は、既存記事のOllamaでローカルLLMをPCに導入して使うで紹介しています。
Ollamaインストール後は、Web UIやCLIコマンドでモデル選択することでGemma 4を簡単に使うことができます。
Web UIはチャット形式で試しやすく、CLIは直接モデルを指定して実行できるため開発や細かな操作に向いています。
気軽に触ってみたいならWeb UI、アプリ連携やスクリプト利用まで視野に入れるならCLIやAPIが向いています。
用途に応じて入口を選べるのは、Ollamaの大きな強みです。
Web UIで使う
Web UIのSelecta modelから目的のGemma 4モデルを選択して使用します。
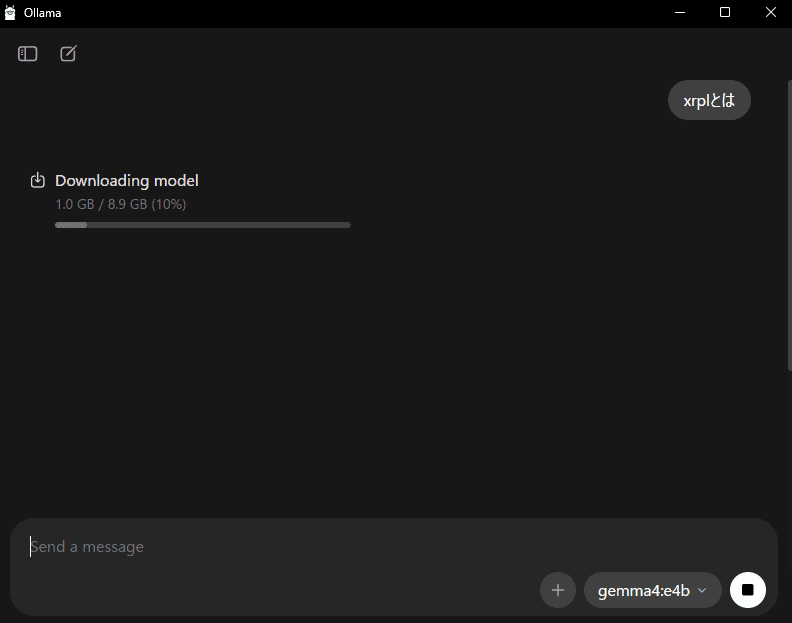
チャットを開始すると選択したモデルのダウンロードが始まります。
下記は、gemma4:e4b選択後にチャットを開始した状態です。
CLIで使う
CLIは、ターミナルでollama <コマンド名> の形式で入力することで、使います。
ollama run <モデル名>で、モデルを起動し、チャットを(未取得ならダウンロードから)開始できます。
軽量モデルの gemma4:e2bを使いたい場合は、以下の様に入力します。
ollama run gemma4:e2b以下は、gemma4:e2bを実行し、簡単なチャットを行った例(ターミナル画面)です。
gemma4:e2bを実行し、簡単なチャットを行う
PS C:\Users\Owner> ollama run gemma4:e2b
pulling manifest
pulling 4e30e2665218: 100% ▕██████████████████████████████████████████████████████████▏ 7.2 GB
pulling 7339fa418c9a: 100% ▕██████████████████████████████████████████████████████████▏ 11 KB
pulling 56380ca2ab89: 100% ▕██████████████████████████████████████████████████████████▏ 42 B
pulling c6bc3775a3fa: 100% ▕██████████████████████████████████████████████████████████▏ 473 B
verifying sha256 digest
writing manifest
success
>>> リンゴが3つあります。1つを食べて、もう1つを友達にあげました。その後、新しく2つ買いました。今、手元には何個のリンゴが
... ありますか? ステップバイステップで考えて教えてください。
Thinking...
Here's a thinking process to arrive at the suggested answer:
1. **Analyze the Request:** The user presents a word problem and asks for the final count of apples, requiring a
step-by-step explanation.
* Initial state: 3 apples.
* Action 1: Ate 1 apple.
* Action 2: Gave 1 apple to a friend.
* Action 3: Bought 2 new apples.
* Goal: Find the current total.
2. **Step-by-Step Calculation:**
* **Step 1: Starting amount.**
* Start: 3
* **Step 2: Eating.** (1 is removed)
* Calculation: 3 - 1 = 2
* Current state: 2
* **Step 3: Giving away.** (1 is removed)
* Calculation: 2 - 1 = 1
* Current state: 1
* **Step 4: Buying new ones.** (2 are added)
* Calculation: 1 + 2 = 3
* Current state: 3
3. **Final Review and Formatting:** The final answer is 3. The explanation must be clear and follow the steps
requested by the user. (Ensure the tone is helpful and direct.)
4. **Construct the Japanese Response.** (This aligns with the required output.)
...done thinking.
ステップバイステップで考えていきましょう。
### ステップ1:最初に持っていたリンゴの数
最初は **3個** のリンゴがあります。
### ステップ2:1つを食べた
3個から1個を食べました。
$$3 - 1 = 2$$
この時点で、手元には **2個** のリンゴが残っています。
### ステップ3:1つを友達にあげた
2個から1個を友達にあげました。
$$2 - 1 = 1$$
この時点で、手元には **1個** のリンゴが残っています。
### ステップ4:新しく2つ買った
1個に加えて、新しく2つ買いました。
$$1 + 2 = 3$$
この時点で、手元には **3個** のリンゴがあります。
---
**答え:今、手元には3個のリンゴがあります。**
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.
Use \path\to\file to include .jpg, .png, .webp images, or .wav audio files.
>>> /bye
PS C:\Users\Owner>ストレージにロードされたモデルは、以下のコマンドで確認できます。
ollama listまた、メモリ上に存在し実行中のモデルの確認は、以下のコマンドで確認できます。
ollama psデフォルト設定では、最後に応答してから5分間何も入力がないと、Ollamaはメモリを空けるためにモデルを自動的にアンロード(解放)します。
強制的にメモリを開放する場合は、以下のコマンドを使います。
ollama stop モデル名モデルを削除してストレージ容量を空ける場合は、以下のコマンドを実行します。
ollama rm モデル名以下は、gemma4:e2bの実行から削除までの実行例(ターミナル画面)です。
PS C:\Users\Owner> ollama list
NAME ID SIZE MODIFIED
gemma4:e2b 7fbdbf8f5e45 7.2 GB 10 minutes ago
PS C:\Users\Owner> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
PS C:\Users\Owner> ollama rm gemma4:e2b
deleted 'gemma4:e2b'
PS C:\Users\Owner> ollama list
NAME ID SIZE MODIFIED
PS C:\Users\Owner> ollama run gemma4:e2b
pulling manifest
pulling manifest
pulling 4e30e2665218: 100% ▕██████████████████████████████████████████████████████████▏ 7.2 GB
pulling 7339fa418c9a: 100% ▕██████████████████████████████████████████████████████████▏ 11 KB
pulling 56380ca2ab89: 100% ▕██████████████████████████████████████████████████████████▏ 42 B
pulling c6bc3775a3fa: 100% ▕██████████████████████████████████████████████████████████▏ 473 B
verifying sha256 digest
writing manifest
success
>>> /bye
PS C:\Users\Owner> ollama list
NAME ID SIZE MODIFIED
gemma4:e2b 7fbdbf8f5e45 7.2 GB 12 seconds ago
PS C:\Users\Owner> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
gemma4:e2b 7fbdbf8f5e45 7.9 GB 73%/27% CPU/GPU 4096 4 minutes from now
PS C:\Users\Owner> ollama stop gemma4:e2b
PS C:\Users\Owner> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
PS C:\Users\Owner> ollama rm gemma4:e2b
deleted 'gemma4:e2b'
PS C:\Users\Owner> ollama list
NAME ID SIZE MODIFIED
PS C:\Users\Owner>参考:公式ドキュメント(CLIリファレンス):Ollama CLI Reference
CLIでのマルチモーダル(画像解析)を実行
1.モデルの起動:
ollama run gemma4:e2b2.解析スクリプトの実行:
以下のスクリプト(ollama_vision_test.py)を使用して、画像をBase64エンコードして送信します。
import base64
import requests
# 1. 画像パスとOllamaのURLを設定
IMAGE_PATH = r"画像ファイルへのパス"
API_URL = "http://localhost:11434/api/chat"
# 2. 画像をBase64エンコード
with open(IMAGE_PATH, "rb") as f:
base64_image = base64.b64encode(f.read()).decode('utf-8')
# 3. Ollama APIへリクエスト送信
# OllamaのAPIは 'images' フィールドにBase64文字列のリストを受け取ります
response = requests.post(API_URL, json={
"model": "gemma4:e2b",
"messages": [
{
"role": "user",
"content": "この画像を日本語で詳しく説明して。",
"images": [base64_image] # ここがOllama特有の形式です
}
],
"stream": False
})
# 結果を表示
print(response.json()['message']['content'])このvision_test.pyを実行(python ollama_vision_test.py)することで、画像を解析できます。

モデルの起動
> ollama run gemma4:e2b
pulling manifest
pulling 4e30e2665218: 100% ▕██████████████████████████████████████████████████████████▏ 7.2 GB
pulling 7339fa418c9a: 100% ▕██████████████████████████████████████████████████████████▏ 11 KB
pulling 56380ca2ab89: 100% ▕██████████████████████████████████████████████████████████▏ 42 B
pulling c6bc3775a3fa: 100% ▕██████████████████████████████████████████████████████████▏ 473 B
verifying sha256 digest
writing manifest
success
>>> /exit
スクリプトの実行
> python ollama_vision_test.py
この画像は、リラックスした雰囲気のバスルームのシーンを捉えた写真です。全体的に温かく、癒やされる、心地よい感覚が伝わってきます。
以下に詳細な説明を記述します。
### 画像の構成と内容
**1. メインの被写体(左側)**
* **人物:** 若い女性が写っています。彼女は髪を濡らし、水しぶきの中でリラックスしている様子です。
* **表情と雰囲気:** 彼女は目を閉じており、顔には穏やかな笑みが浮かんでいます。これは、水がもたらす安らぎや心地よさを満喫している様子を示しています。肌は水滴で光り輝いており、非常に心地よい、癒やしの瞬間が捉えられています。
* **状況:** 彼女はシャワーや湯船の中で、水しぶきに包まれています。
**2. 背景と設定(右側)**
* **空間:** 写真の右側には、大きなガラスの仕切り(または鏡)があり、その向こう側に別の空間が映っています。
* **別のシーン:** その映り込みの中には、浴槽に浸かっている足や脚の一部が見え、全体としてバスルームやスパのような、清潔でモダンな空間が示唆されています。
### 全体の印象とテーマ
この画像は、**「リラクゼーション」「癒やし」「清潔感」**というテーマを強く表現しています。水と光の使い方が非常に美しく、自然で穏やかな、贅沢なバスタイムの瞬間を切り取ったスナップショットです。
**まとめると、この画像は、水の中で心からリラックスし、心地よい安らぎを感じている女性の、平和で美しいひとときを描いています。**
>
Gemma 4をOllamaで使うメリット
Gemma 4をOllamaで使うメリットは、大きく3つあります。
第一に、ローカル実行とAPI実行の両方に広げやすいことです。
Web UIで試し、CLIで動かし、必要に応じてAPIに組み込む流れが作れます。
第二に、画像入力まで含めたマルチモーダル利用が視野に入ることです。
公式ページでは、Gemma 4系はText/Image入力対応として案内されています。
第三に、軽量側から大規模側まで段階的に試せることです。
e2b/e4bの軽量寄りから、26b/31b、さらに31b-cloudまで用意されているため、PC性能や用途に合わせて選べます。
まとめ
Gemma 4はOllama上でかなり相性の良い追加候補です。
Ollamaの強みである簡単な導入、CLI、API、Web UIを活かしながら、Gemma 4の推論・コーディング・エージェント的処理・画像理解を試せます。
まずは gemma4:e2b や gemma4:e4b で軽く試し、必要に応じて 26b や 31b、クラウド版へ広げる流れが現実的です。
ローカルAIを学びたい人にも、実務で検証したい人にも、Gemma 4はOllama上で試す価値のあるモデルと言えます。