
この記事のポイント
AIエージェントは、高性能なLLMだけで成立するものではありません。実用化には、コンテキスト管理、計画、ツール接続、評価、ガードレールを含む内部構造の設計が欠かせません。
本記事では、AIエージェントを6つの層で整理し、ワークフロー型との違い、モデル以上に重要な「状態管理能力」、さらに失敗しやすい4つのパターンを分かりやすく解説します。
AIエージェントという言葉は広く使われるようになりましたが、その本質は単に「会話が上手なAI」ではありません。
実用的なAIエージェントとは、与えられた目標に応じて状況を判断し、必要に応じて外部ツールを使い、途中結果を踏まえて次の行動を選びながら、複数ステップの処理を進める仕組みです。
つまり、注目すべきなのはモデル単体の性能ではなく、モデルがどのような構造の中で動いているかです。
近年は大規模言語モデルの性能向上が注目されがちですが、実務でエージェントの成否を分けるのは、モデルの賢さだけではありません。
どの情報を持たせるのか、どのタイミングでツールを呼び出すのか、実行結果をどう評価するのか、どこで停止させるのかといった設計が、そのまま安定性と実用性に直結します。
だからこそ、AIエージェントを理解するには、モデルの性能だけでなく、その内部構造まで見ていく必要があります。
AIエージェントは「モデル」ではなく「ループ」で理解する
AIエージェントの内部構造を理解するとき、まず押さえるべきなのは、エージェントが単発の応答ではなく「ループ」で動くという点です。
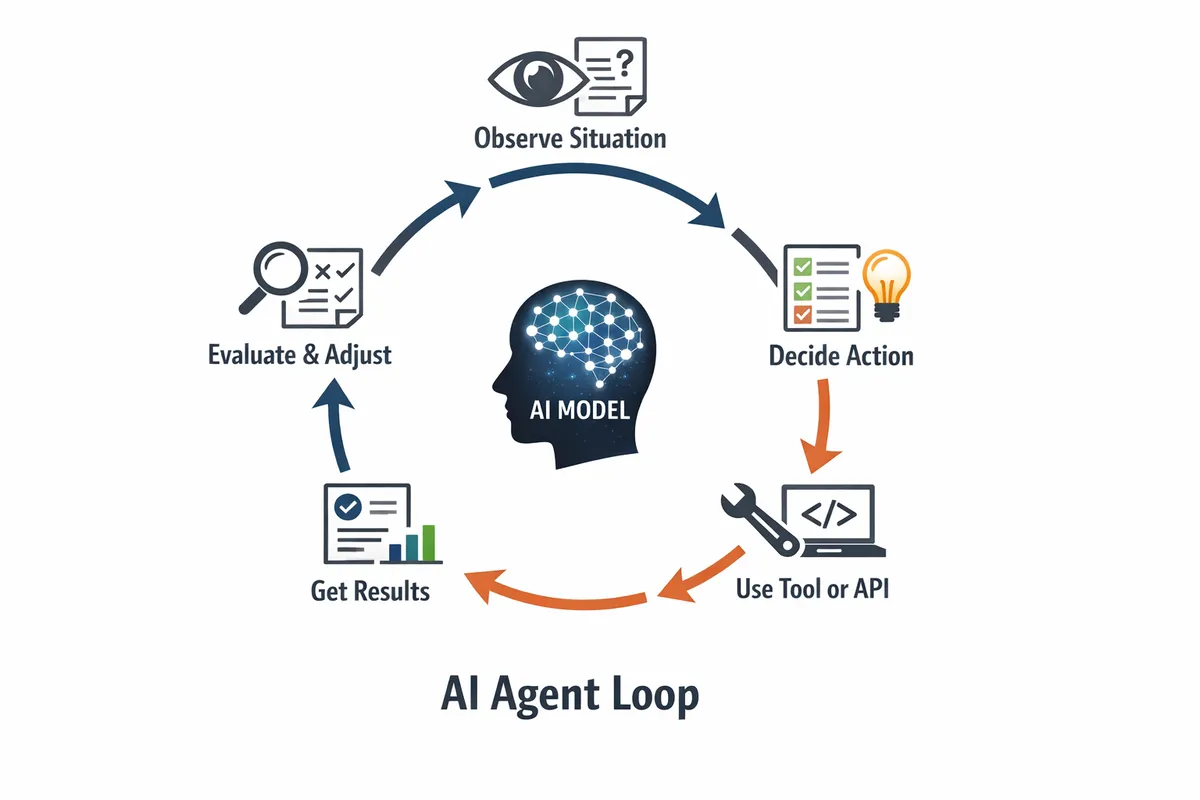
モデルが現在の状態を見て次の行動を決め、必要ならツールを呼び出し、その結果を受けて再び判断する。
この繰り返しがエージェントの中心です。LangChainのドキュメントでも、信頼できるエージェントを作るには、各ステップとステップ間で何が起こるかを制御する必要があると説明されています。
この視点に立つと、AIエージェントの品質は「どのモデルを使ったか」だけでは決まりません。
重要なのは、どの情報を見せるか、どんなツールを使わせるか、どこで止めるか、失敗したときにどう戻すかです。
Anthropicも、実際に成功しているエージェントは複雑な専用フレームワークより、シンプルで組み合わせやすいパターンの積み重ねで作られていると述べています。
なぜ高性能LLMだけでは不十分なのか
大規模言語モデルは推論や要約の起点として非常に強力ですが、それだけで実務の多段処理を完結できるわけではありません。
たとえば、外部データを参照する、ファイルを読む、APIを呼ぶ、結果を検証する、
権限に応じて動作を変えるといった処理は、モデル単体では担えません。
OpenAIのガイドでも、ツール設計やガードレールが整って初めて、エージェントは安全かつ予測可能に動くと説明されています。
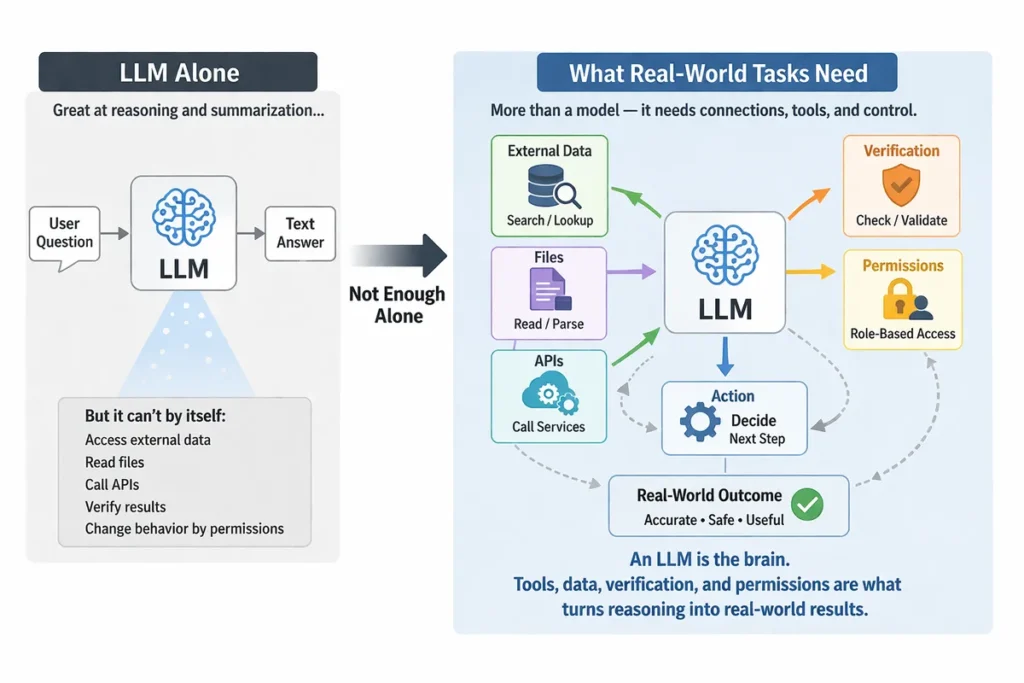
さらに、モデルは与えられた文脈の中でしか判断できません。
LangChainは、エージェントの信頼性を左右する中核課題としてコンテキスト設計を位置づけており、「正しい情報とツールを、正しい形式で与えること」が重要だとしています。
つまり、実装上の差はモデル名よりも、コンテキストの設計とツールの接続面に出やすいのです。
AIエージェントを6つの層で見る
AIエージェントの内部構造は複雑に見えますが、役割ごとに分けると理解しやすくなります。
IBMは、AIエージェントを認識、推論、計画、メモリー、ツール連携、学習など複数の構成要素をもつシステムとして説明しています。
これを実装視点で整理すると、エージェントは次の6層で捉えると分かりやすくなります。
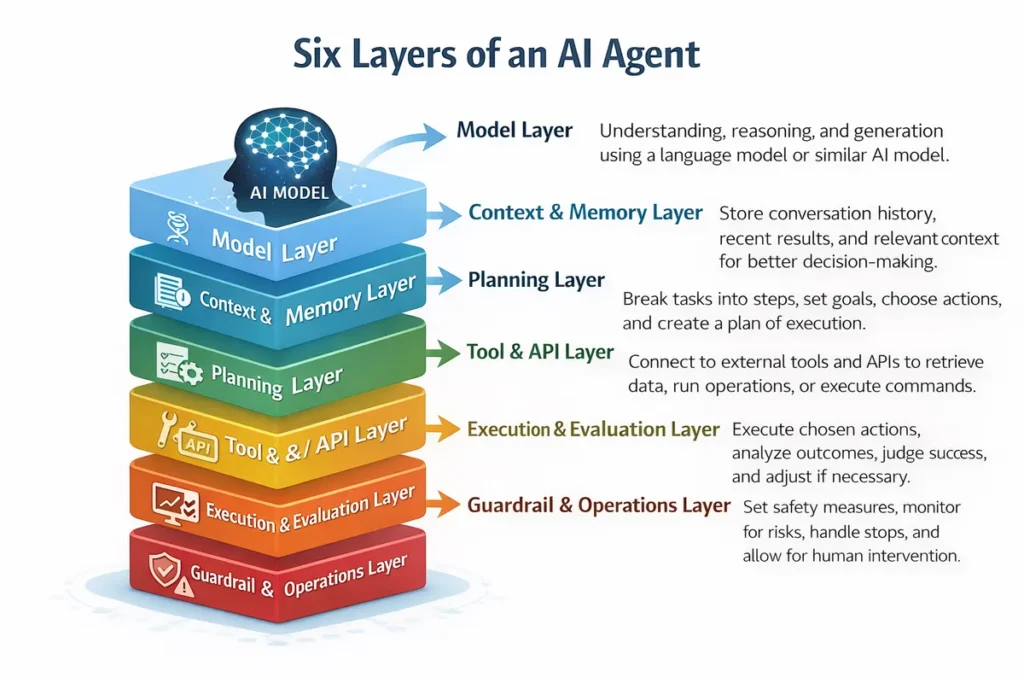
モデル層
モデル層は、入力の理解、推論、要約、次の行動候補の生成を担います。
ここはエージェントの頭脳にあたりますが、単体では完結しません。
モデル層は、後続のコンテキスト設計やツール接続が整って初めて安定して機能します。
コンテキスト・メモリ層
ここでは会話履歴、途中結果、ユーザー状態、参照資料などを扱います。
長いタスクほど、何を保持し、何を圧縮し、何を捨てるかが重要になります。
LangChainは、エージェントの各ステップだけでなく、ステップ間でどの情報を受け渡すかが信頼性の鍵だと説明しています。
参考:Context engineering in agents – Docs by LangChain
計画層
計画層は、目標を中間タスクへ分解し、次の行動を選ぶ部分です。
まず単一エージェントで十分かを見極め、必要な場合にのみ複数エージェント構成へ広げるのが実務的だと案内しています。
計画層が弱いと、エージェントは場当たり的に動きやすくなります。
ツール接続層
ツール接続層は、検索、ファイル操作、データベース、外部API、コード実行などを担当します。
ここがあることで、エージェントは「答えるだけ」から「処理を進める」存在へ変わります。
MCPは、AIアプリケーションを外部のデータソース、ツール、ワークフローへ接続するためのオープン標準として整備されています。
実行・評価層
ツールを呼んだあと、その結果が正しいか、目的に近づいたか、別の経路が必要かを判断するのがこの層です。
エージェントは、実行して終わりではなく、実行結果を踏まえて次の一手を選び直す必要があります。
明確なツール定義とオーケストレーションが安定動作の前提です。
ガードレール・運用層
ガードレール・運用層は、安全性、権限制御、監視、停止条件、人間確認などを扱います。
ツール利用時の安全策や人間介在の仕組みは重視であり、MCPでも認可や監査の必要性です。
高性能なエージェントほど、この層を後付けにできません。
参考:Building Governed AI Agents – A Practical Guide to Agentic Scaffolding
ワークフロー型とエージェント型は何が違うのか
AIエージェントを考えるうえで混同されやすいのが、ワークフロー型との違いです。
ワークフロー型は、あらかじめ定められた道筋に沿って処理を進めます。
一方、エージェント型は、途中でどのツールを使うか、何を優先するか、いつ終えるかを、その場の文脈を見て動的に判断します。
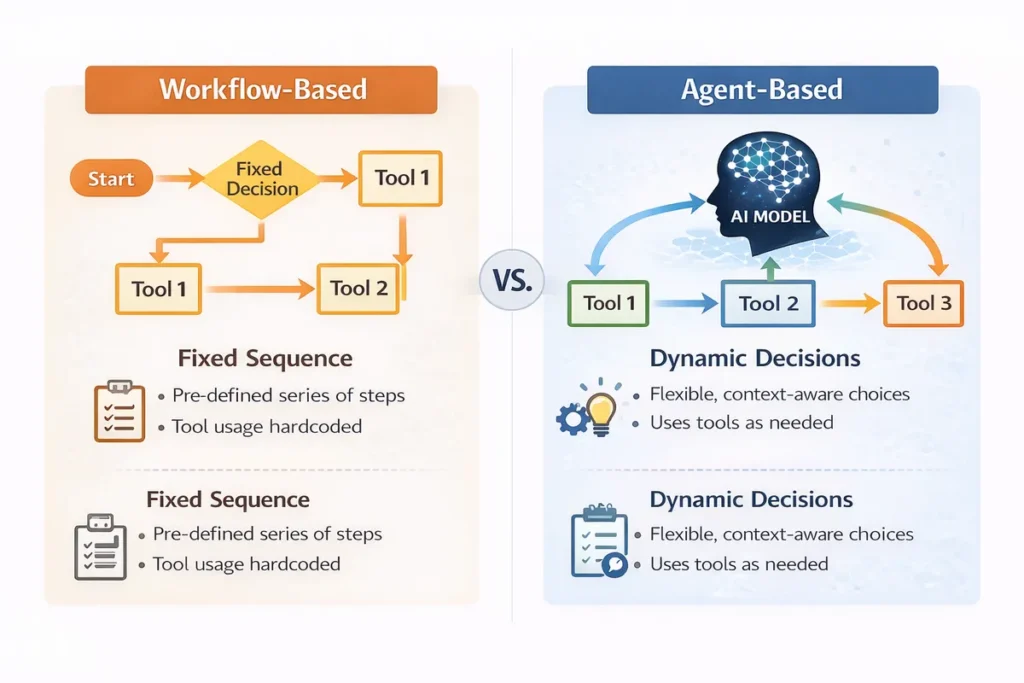
標準的なワークフローとエージェント型の違いは、固定された制御と動的な制御の差といえます。
ただし、すべての処理をエージェント化すべきではありません。
複雑な構成に飛びつくより、シンプルで合成可能なパターンから始めるほうが成功しやすいといえます。
予測可能性が重要な処理はワークフローで十分なことが多く、自律性が本当に必要な部分だけをエージェント化するほうが、コストも安定性も改善しやすくなります。
AIエージェントの本当の分岐点は「自律性」ではなく「状態管理能力」である
AIエージェントの説明では、「どれだけ自律的に動けるか」が前面に出がちです。
しかし、主要な技術資料を横断して見ると、実装の成否を分ける本当の分岐点は、自律性そのものよりも、状態をどれだけ安全に保持し、評価し、更新し、必要なら戻せるかにあります。
LangChainがコンテキスト制御を重視し、OpenAIがガードレールとオーケストレーションを重視し、MCPが接続面と権限管理を重視しているのは、いずれもエージェントの成否が“状態管理”に依存するからです。
この観点から見ると、AIエージェントの成否は状態管理の設計に強く依存しており、その破綻パターンは大きく4つに分類できます。
以下は単なる構成要素の紹介ではなく、どこが壊れやすいかを見抜くための実装上の分類です。
状態肥大型
会話履歴や途中結果を積み上げすぎて、必要な情報よりノイズのほうが増えてしまう型です。
文脈が増えるほど賢くなるように見えて、実際にはコスト、遅延、判断のぶれが増しやすくなります。
長時間動くエージェントほど、短期記憶と長期記憶を分け、何を要約して何を保持するかを設計しなければなりません。
評価欠落型
ツールを呼び出せること自体をゴールにしてしまい、その結果が正しいか、目的に近づいたかを十分に検証しない型です。
検索結果を取得できたことと、正しい判断に到達したことは別です。
エージェントに必要なのは実行能力だけではなく、結果を見て軌道修正する評価能力です。
制御境界不明型
停止条件、依存関係、再試行回数、権限境界が曖昧なまま自律性だけを上げてしまう型です。
MCPの認可設計や、ガードレール設計が重視されるのは、エージェントが外部システムへアクセスする以上、柔軟性より先に境界管理が必要だからです。
制御境界がないエージェントは、賢いというより危ういシステムになりやすいと言えます。
過剰自律型
本来は固定手順で十分な処理までエージェント化してしまい、コストと不安定さだけを増やす型です。
まずは単純な構成から始め、必要に応じて広げることが必要です。
高度な構成が常に優れているわけではなく、問題に対してちょうどよい自律性を選ぶことが重要です。
2026年時点での実用的な設計原則
現時点で最も現実的なのは、強い単一エージェントを中心に置き、明確なツール群と厳格なガードレールを組み合わせる設計です。
いきなりマルチエージェントにするのではなく、まずはシンプルな単一構成から始めるのがコツです。
まずは単一エージェントから着手し、真に必要性が生じた段階でマルチエージェントへと拡張するアプローチを推奨しています。
シンプルで汎用性の高い構成を維持することで、デバッグの効率化と運用面での安定性を確保しやすくなるためです。
信頼性の高いエージェントを構築する鍵は、個々のプロセスと工程間の情報制御にあります。
AI設計の本質は、単に『高性能なモデルを採用すること』ではなく、『エラーを未然に防ぐ堅牢な構造を設計すること』に他なりません。
まとめ
AIエージェントの内部構造を理解する鍵は、モデル単体ではなく、モデル、コンテキスト、計画、ツール、評価、運用をひとつのループとして捉えることです。
エージェントは、賢い会話システムの延長ではなく、外部世界と接続しながらタスクを前に進めるためのシステム設計そのものです。
そして、2026年時点で本当に差がつくのは、自律性の高さそのものではありません。
状態を安全に管理し、必要なら戻し、監視し、制御できる構造を持っているかどうかです。
AIエージェントの競争力は、今後ますます「どのモデルか」だけでなく、「どんな内部構造か」で決まっていくはずです。

