
2026年4月3日、国産LLMとして注目される 「LLM-jp-4 32B-A3B」 が公開されました。
同時期にはGoogleの 「Gemma 4」 が登場し、オープンLLMの分野は大きく盛り上がりを見せています。
さらに、OpenAIの 「GPT-OSS」(2025年8月5日リリース)も引き続き有力な選択肢として存在感を放っています。
今回は、これらの主要モデルを Windows 11 のローカル開発環境で動かし、日本語でどれだけ実用的に使えるのかを詳しく検証しました。
ローカル環境での評価方法の流れ
今回の比較検証では、条件を公平に保つため、すべてのモデルを同一のローカルマシン上で実行しました。
回答の生成から自動採点まで、一連の作業をどのように構築したのか、その具体的な手順を解説します。
検証環境
今回のテストは、一般的なローカル開発環境を想定し、以下の構成で実施しました。
- OS:Windows 11
- ターミナル:VS Code / Git Bash
- 実行環境:Python 3.x(venvによる仮想環境)
- 評価指標:ELYZA-tasks-100
開発者が比較的導入しやすく、再現性の高いシンプルな構成でテストしています。
| モデル名 | パラメータ数 | サイズ | 特徴 |
| Gemma-4-26b-a4b-it | 26B (Active 4B) | 17.99 GB | Googleの最新鋭。高い論理性と日本語力。 |
| LLM-jp-4-32B-a3B-thinking | 32B (Active 3B) | 21.40 GB | NII主導。MoE採用の軽量・高機能な国産LLM。 |
| OpenAI/GPT-OSS-20b | 20B | 12.11 GB | OpenAI初の本格オープンソース版。 |
「LLM as a Judge」による自動評価の仕組み
100問の回答を人間が一つずつ採点するのは現実的ではありません。
そこで、GPT-5.4 miniを「審判」として起用するLLM as a Judgeを採用しました。
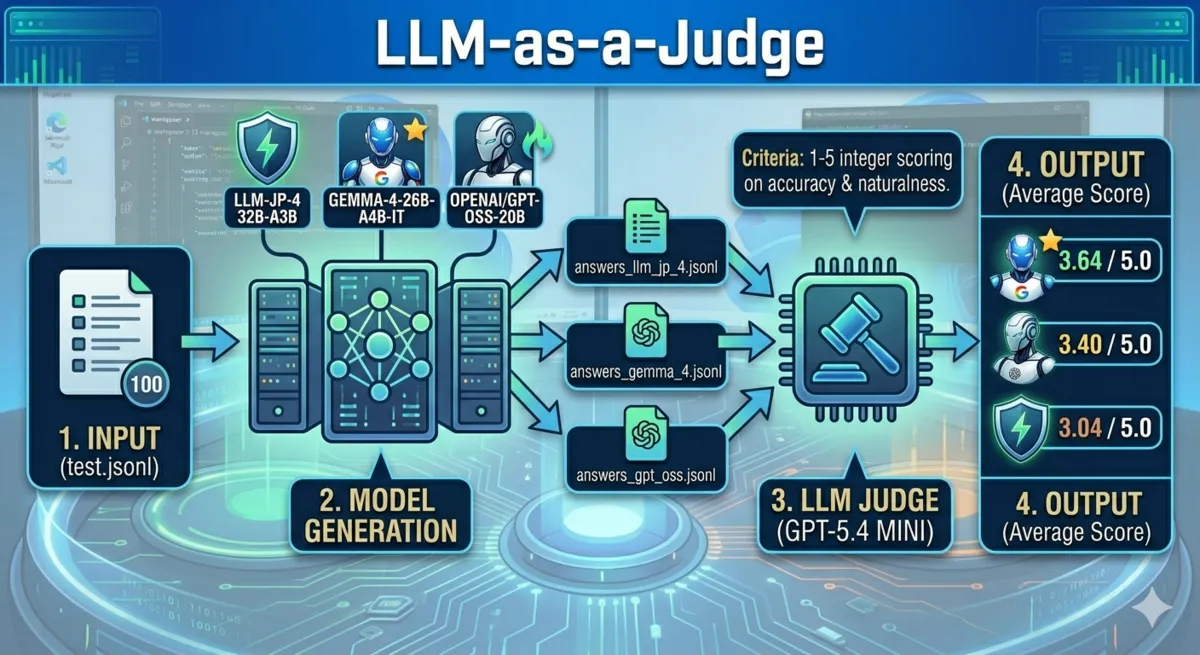
評価用スクリプトにより、各回答に対して「指示に正しく従っているか」「日本語が自然か」を1〜5点で厳密にスコア化しています。
ローカルLLM評価データの生成
今回の検証では、LM Studio 0.4.0 のGUI画面を使用し、各モデルを順番に切り替えながら、以下の手順で評価データを生成しました。
回答生成スクリプトの作成
「ローカルAPIサーバー(OpenAI互換)」に接続して回答を取得するスクリプトです。
- 入力:
LYZA-tasks-100 (test.jsonl): 100問の日本語指示が含まれたデータセット - 出力:
「問題(input_text)」と、それに対してモデルが生成した「回答(output_text)」がペアになった100行のデータ(answers_モデル名.jsonl)
gen_answers_lmstudio.py
import json
import openai
from datasets import load_dataset
from tqdm import tqdm
# LM Studioのサーバー設定
client = openai.OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
# ELYZA-tasks-100の読み込み
ds = load_dataset("elyza/ELYZA-tasks-100", split="test")
results = []
for i, item in enumerate(tqdm(ds)):
completion = client.chat.completions.create(
model="local-model", # LM Studioではこの指定でOK
messages=[{"role": "user", "content": item["input"]}]
)
response_text = completion.choices[0].message.content
results.append({
"task_id": i,
"input_text": item["input"],
"output_text": response_text
})
# 結果を保存
with open("answers_llm_jp_4.jsonl", "w", encoding="utf-8") as f:
for res in results:
f.write(json.dumps(res, ensure_ascii=False) + "\n")gen_answers_gemma.py
import json
import openai
from datasets import load_dataset
from tqdm import tqdm
# LM Studioのサーバー設定
client = openai.OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
# ELYZA-tasks-100の読み込み
ds = load_dataset("elyza/ELYZA-tasks-100", split="test")
results = []
for i, item in enumerate(tqdm(ds)):
completion = client.chat.completions.create(
model="local-model", # LM Studioではこの指定でOK
messages=[{"role": "user", "content": item["input"]}]
)
response_text = completion.choices[0].message.content
results.append({
"task_id": i,
"input_text": item["input"],
"output_text": response_text
})
# 結果を保存
with open("answers_gemma_4.jsonl", "w", encoding="utf-8") as f:
for res in results:
f.write(json.dumps(res, ensure_ascii=False) + "\n")
gen_answers_gpt_oss
import json
import openai
from datasets import load_dataset
from tqdm import tqdm
# LM Studioのサーバー設定
client = openai.OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
# ELYZA-tasks-100の読み込み
ds = load_dataset("elyza/ELYZA-tasks-100", split="test")
results = []
for i, item in enumerate(tqdm(ds)):
completion = client.chat.completions.create(
model="local-model", # LM Studioではこの指定でOK
messages=[{"role": "user", "content": item["input"]}]
)
response_text = completion.choices[0].message.content
results.append({
"task_id": i,
"input_text": item["input"],
"output_text": response_text
})
# 結果を保存
with open("answers_gpt_oss.jsonl", "w", encoding="utf-8") as f:
for res in results:
f.write(json.dumps(res, ensure_ascii=False) + "\n")ステップ1:LM Studio GUIでのモデル・ロード
まず、LM Studioで検証対象のモデルをロードします。
Gemma-4-26b-a4b-it、OpenAI/GPT-oss-20b の検証時には、ロードを切り替えます。
ステップ2:回答生成スクリプトの実行
モデルがロードされ、ローカルサーバーが「Ready」になった状態で、Git Bashから各モデル専用のスクリプトを実行します。
回答生成スクリプト実行コマンド
# LLM-jp-4の回答生成
$ ./venv/Scripts/python.exe gen_answers_lmstudio.py --model llm-jp-4
# (GUIでモデルをGemma 4に切り替え)
# Gemma 4の回答生成
$ ./venv/Scripts/python.exe gen_answers_gemma.py
# (GUIでモデルをGPT-OSSに切り替え)
# GPT-OSSの回答生成
$ ./venv/Scripts/python.exe gen_answers_gpt_oss.py評価用スクリプトによる評価データの検証
下記の評価用スクリプト(evaluate.py)を作成し、各回答に対して「指示に正しく従っているか」「日本語が自然か」を1〜5点で厳密にスコア化します。
評価用スクリプト(evaluate.py)の作成
このスクリプトは、GPT-5.4 miniが「問題」「正解例」「モデルの回答」を比較し、論理性や正確性を基準に1〜5点で評価を行うものです。
さらに、各問題ごとの得点に加えて、最終的に100問全体の平均スコアも出力します。
evaluate.py
import json
import os
import openai
from tqdm import tqdm
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--pred_path", type=str, required=True, help="採点対象のjsonlファイルパス")
parser.add_argument("--model", type=str, default="gpt-5.4-mini", help="審判として使うモデル名")
args = parser.parse_args()
# 環境変数からAPIキーを取得
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
print("エラー: OPENAI_API_KEY が設定されていません。")
return
client = openai.OpenAI(api_key=api_key)
# データの読み込み
with open(args.pred_path, "r", encoding="utf-8") as f:
lines = f.readlines()
print(f"--- 採点開始: {args.pred_path} (Model: {args.model}) ---")
scores = []
# 1問ずつGPT-5.4 miniに投げる
for line in tqdm(lines):
data = json.loads(line)
# 採点用プロンプト
prompt = f"""以下の回答を1〜5点の整数で採点してください。
問題: {data['input_text']}
回答: {data['output_text']}
採点基準:
5点: 完璧。指示に全て従い、日本語が自然で正確。
4点: ほぼ完璧だが、極めて些細な欠点がある。
3点: 指示には従っているが、内容が不十分または少し不自然。
2点: 指示の一部を無視している、または誤りが目立つ。
1点: 全く指示に従っていない、または内容が完全に誤っている。
出力は以下のJSON形式のみで返してください:
{{"score": 整数}}"""
try:
response = client.chat.completions.create(
model=args.model,
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"} # JSONモードで確実に数字を取る
)
res_data = json.loads(response.choices[0].message.content)
score = int(res_data["score"])
scores.append(score)
except Exception as e:
print(f"エラー(スキップ): {e}")
continue
if scores:
average = sum(scores) / len(scores)
print(f"\n==============================")
print(f"【結果】 {args.pred_path}")
print(f"平均スコア: {average:.2f} / 5.0")
print(f"有効回答数: {len(scores)} / {len(lines)}")
print(f"==============================\n")
if __name__ == "__main__":
main()評価用スクリプト(evaluate.py)の実行
OpenAI APIキーの設定を環境変数に設定します。
export OPENAI_API_KEY='sk-...' # 取得したAPIキーを入力各LLMの回答に対して、評価用スクリプト(evaluate.py)を実行します。
# LLM-jp-4 の採点
./venv/Scripts/python.exe evaluate.py --pred_path "answers_llm_jp_4.jsonl"
# Gemma-4 の採点
./venv/Scripts/python.exe evaluate.py --pred_path "answers_gemma_4.jsonl"
# gpt-oss-20b の採点
./venv/Scripts/python.exe evaluate.py --pred_path "answers_gpt_oss_20b.jsonl"総合結果の比較
判定モデルとして gpt-5.4-mini(reasoning_effort設定含む最新版)を使用し、5点満点で評価した結果です。
| モデル名 | 平均スコア | 判定速度 | 特徴・構成 |
| Gemma 4 26B A4B IT | 3.64 | 1.27it/s | Google / MoE (Active 4B) |
| OpenAI gpt-oss 20B | 3.40 | 1.13it/s | OpenAI / Dense 20B |
| LLM-jp-4 32B-A3B thinking | 3.04 | 1.26it/s | NII / MoE (Active 3B) |
詳細分析
① Gemma 4 26B A4B IT(スコア: 3.64)
【分析】 今回の検証で最高スコアを記録しました。
Googleの最新アーキテクチャであるMoE(4B活性)の効果が顕著です。
ELYZA-tasks-100のような複雑な指示においても、論理的な破綻が少なく、かつ自然な日本語を出力できていることが推測されます。
- 強み: 指示従順性と文脈理解のバランスが非常に高い。
- 判定速度: 最も安定しており、APIとの相性(出力の簡潔さ)も良好。
② OpenAI gpt-oss 20B(スコア: 3.40)
【分析】 2番手ですが、3.40というスコアは「実用レベル」の非常に高い水準です。
OpenAIが公開したオープンウェイトモデルとして、特定の言語に偏らず高い指示追従能力を持っています。
- 注目点: 判定速度が 1.13it/s と少し遅めです。これは、回答が他のモデルより長文(詳細)であったために、ジャッジモデル(gpt-5.4-mini)の処理トークン量が増えた可能性が高いです。
③ LLM-jp-4 32B-A3B thinking(スコア: 3.04)
【分析】 国産モデルとして大健闘していますが、世界のトップランナーと比較するとスコア上は一歩譲る形となりました。
しかし、本モデルは Active 3B という極めて軽量な推論コストで動作しています。
- 考察: 「3.0以上」は、指示の意味は正しく理解できているレベルです。
「thinking」モデルとしての思考過程が日本語の微細な表現に影響している可能性もあります。
2026年4月3日に同時期公開された最新モデルを比較した結果、ローカルLLMの進化は予想を遥かに上回るスピードで進んでいることが分かりました。
まとめ:2026年春、ローカルLLMの新時代
2026年4月3日に同時期公開された最新モデルを比較した結果、ローカルLLMの進化は予想を上回るスピードで進んでいることが分かりました。
| 評価項目 | 最優秀モデル | 特徴 |
| 総合スコア | Gemma-4-26b-a4b-it | 圧倒的な指示従順性と自然な日本語。 |
| バランス | OpenAI/gpt-oss-20b | 安定した汎用性。回答の丁寧さも光る。 |
| 効率性 | LLM-jp-4 32B-A3B | Active 3Bという極小コストで3点台をマーク。 |
どのモデルを選ぶべきか?
- 究極の精度を求めるなら:Gemma 4 現状、ローカル環境で動かせる日本語対応モデルとしては最高峰の完成度です。
- 安定した開発基盤なら:GPT-OSS OpenAIの設計思想が反映されており、多様な指示に対して手堅く応えてくれます。
- 省エネ・国内最適化なら:LLM-jp-4 推論コストの低さは随一。特定の業務知識を覚え込ませる(Fine-tuning)ベースモデルとしても、今後の伸び代が最も期待できます。
参考リンク
- NII プレスリリース:LLM-jp-4 32B-A3B 公開のお知らせ
- Google Cloud: Gemma 4 モデルドキュメント
- OpenAI モデルライブラリ (GPT-OSS)
- Elyza Tasks 100 人間評価システム


