
生成AIを日常業務や開発環境で活用するにあたり、「クラウドではなくローカルPCで動かしたい」というニーズは年々増えています。
特に個人開発者や中小企業では、セキュリティ上の理由やコスト削減の観点から、ローカル実行可能なgpt-ossやGemma、LLaMAaなどのLLM(大規模言語モデル)が注目されています。
そこで役立つのが Ollama やLM StudioなどのローカルLLM実行環境です。
本記事では、ローカルLLM実行環境のうちのOllamaの特徴やインストール方法、Web UIやCLIでの使い方、さらにLM Studioとの比較まで詳しく解説します。
Ollamaとは
Ollamaは、Mac・Windows・Linuxで利用できる ローカルLLM実行環境 です。
従来は大規模GPUや複雑な環境構築が必要だったLLMを、簡単にPCで動かせるように設計されています。
- 1行コマンドでモデルを実行可能(例:
ollama run llama2) - Web UIでChatGPTのようなチャットインターフェースで利用できる
- REST APIにより他のアプリやスクリプトから呼び出し可能
- gpt-ossやGemma、LLaMA、Mistralなど主要オープンソースLLMをサポート
Ollamaのインストール方法
Ollamaは公式サイト Ollama.ai からインストーラをダウンロードして導入できます。
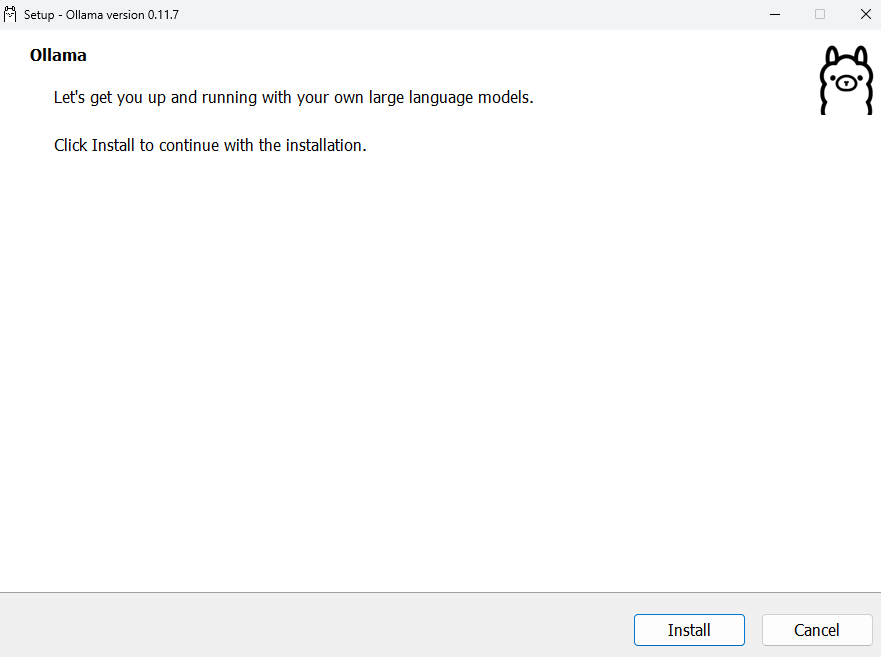
- Windows:OllamaSetup.exeファイルを実行するだけ
- Mac:.dmgをインストール
- Linux:
curl -fsSL https://ollama.com/install.sh | sh
インストールが完了すると、WEB UI画面が表示されます。
ターミナルで ollama --version を入力しても正常にセットアップされているか確認できます。
WindowsでのOllamaのインストール
Ollamaの使用方法
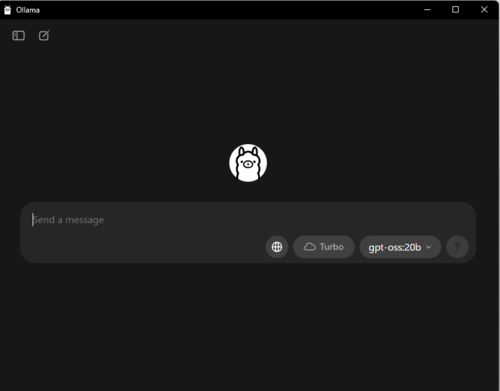
Web UIでの使用方法
インストール後に立ち上げると、黒背景のチャット風UIが表示されます。
ここで入力欄に質問を入力すれば、その場でモデルが応答します。
ローカルLLMの選択とインストール方法
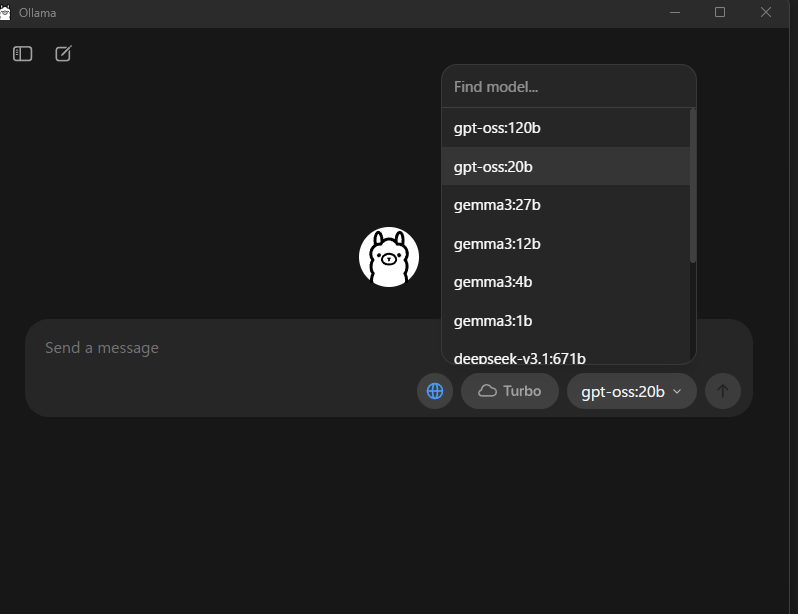
右下の「モデル選択ドロップダウン」から gpt-oss:20b などを選択すると、初回は自動でダウンロードが始まり、完了後に利用可能となります。
「モデル選択ドロップダウン」に使いたいLLMが存在しない場合は、Find modelに使いたいLLM名を入れて検索し、見つかったLLMをクリックします。
選択可能な代表的に指定できるローカルLLM名一覧
- Meta LLaMA系:
llama2:7b/llama3.1:8b - Google Gemma系:
gemma:2b/gemma2:9b - Mistral系:
mistral:7b/mixtral:8x7b - Microsoft Phi系:
phi3:3.8b/phi3:14b - OpenAI OSS系:
gpt-oss:3b/gpt-oss:20b/gpt-oss:120b
gpt-oss20などのWeb検索ツール対応モデルについて
一部のモデル(例:gpt-oss:20b)は、OllamaのUIで「地球マーク(Web検索機能)」が表示されます。
これはアカウントにログインすることで外部検索機能が有効化される特殊モデルです。
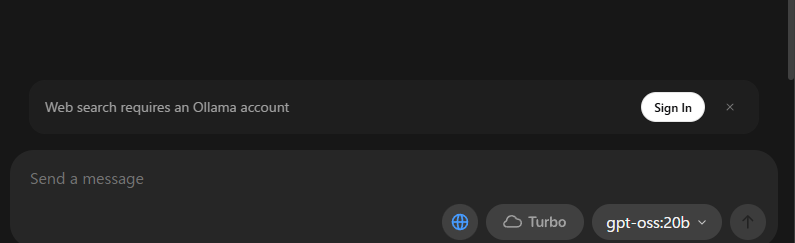
Web検索機能を利用するには、画面の指示に従って公式サイトから無料のOllamaアカウントを作成しサインインする必要があります。
アカウント作成後、プロフィール画面には以下が表示されます:
- ユーザー名とアイコン
- プロフィール欄(編集可能)
- 自分が作成したカスタムモデル一覧(初期状態は “No models” と表示)
ここに表示されるのは「ユーザーが公開・管理しているモデル」のみです。
ローカルPCにダウンロードしたモデルは自動的には反映されません。
(つまり、ローカルで利用しているモデルとアカウント画面に表示されるモデルは別の管理体系です。)
CLIでの使用方法
ターミナルから直接モデルを実行する方法です。
基本構文は以下の通りです。
ollama run モデル名
例:
ollama run gemma:2b
ollama run mistral:7b

他に重要なコマンドオプション
- コンテキスト長の指定:
-c 2048(VRAMが少ない場合に有効) - APIサーバー起動:
ollama serve→http://localhost:11434でREST API呼び出しが可能
料金体系
Ollama自体はオープンソースのソフトウェアであり、ローカル環境(自分のPCやサーバー)にダウンロードしてモデルを実行するためのものです。
そのため、Ollama本体の利用料や、モデルのダウンロード、推論の実行に費用はかかりません。
ただし、各モデルはサイズが大きく(数GB〜十数GB)、ダウンロードには時間とストレージが必要です。
GPUを搭載していないPCでも動作しますが、その場合はCPU処理となり速度が遅くなる傾向があります。
LM Studioとの比較
LM StudioはGUIが充実しており初心者でも扱いやすいのが特徴です。
一方でOllamaはCLIやAPI連携に強く、開発者向けです。
- Ollama:シンプル、API活用向け、開発者向け
- LM Studio:GUI重視、プロンプト実験や研究向け
LM Studio

VRAMとモデル選びの目安
- VRAMサイズは、LLMモデルサイズ × 1.2倍が必要容量の目安です。
- GTX1650(VRAM 4GB)の場合:
gemma:2bやphi3:3.8bが現実的 - RTX 3090/4090クラスなら:
llama3.1:70bやgpt-oss:120bも動作可能
まとめ
Ollamaは、AI LLMをローカル環境で動かしたいユーザーにとって最もシンプルでパワフルな選択肢の一つです。
Web UIで簡単に利用でき、CLIやAPIで開発にも活用可能です。まずは ollama run gemma:2b から試して、自分の環境に合ったモデルを見つけてみてください。

