第5回では、Reviewer AIのレビュー結果をJSON形式で受け渡す仕組みに改善します。
これまでの自然文レビューでは「判定:OK」「判定:このまま公開可能」など出力に揺れがあり、プログラム側の判定が不安定になる可能性がありました。
自然文レビューは人間向けに残しつつ、Python側で処理する判定結果はJSON化し、status によって保存・修正・再レビューの流れを安定させます。
第4回AI記事作成まででできたこと
第3回AI記事作成までは、Planner AI、Writer AI、Reviewer AI、Python側HTMLチェックの途中結果を保存し、どこで失敗したのかを追跡できるようにしました。
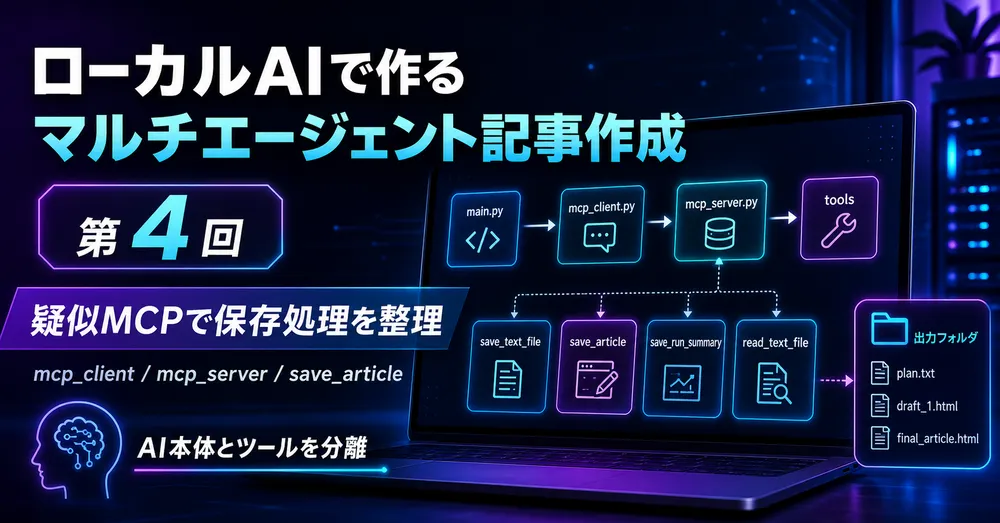
第4回AI記事作成では、その保存処理をさらに整理し、mcp_client.py と mcp_server.py を使った疑似MCPツールとして、AI記事作成の本体とファイル保存処理を分離しました。
流れとしては、次のようになります。
main.py
↓
mcp_client.py
↓
mcp_server.py
↓
保存・読み込みツールこれにより、main.py は記事作成の全体フローに集中し、保存や読み込みなどの処理は疑似MCPツール側に任せられるようになりました。
しかし、ここまで進めると、次の課題が見えてきます。
それが、第2回AI記事作成以降に問題となっていたAIエージェント間で受け渡す情報の形式です。
なぜJSON化が必要なのか
第3回までは、Reviewer AIのレビュー結果を自然文で受け取っていました。
たとえば、次のような形式です。
良い点:
- 構成が分かりやすい
- 読者の検索意図に合っている
修正点:
- 導入文の結論をもう少し前に出すとよい
Writer AIへの具体的な修正指示:
- 冒頭に記事の結論を追加してください
判定:OKこの形式は、人間が読むには分かりやすいです。
しかし、プログラムが読むには少し不安定です。
実際には、Reviewer AIが次のような判定を出すことがありました。
判定:OK判定:
OK判定:このまま公開可能判定:A+人間が見れば「OKに近い」と分かる場合でも、Python側では判断に迷います。
第3回では、この揺れに対応するために、get_review_status() で判定行を読み取る処理を追加しました。
しかし、自然文の出力に頼る限り、出力揺れを完全になくすことは難しいです。
そこで第5回では、Reviewer AIの出力を次のように分けます。
自然文レビュー
→ 人間が読むための説明
JSON判定
→ Pythonが処理するためのデータ第5回AI記事作成での処理変更
第5回AI記事作成では、Reviewer AIのレビュー結果をJSONで受け渡す仕組みにします。
全体像は次の通りです。
Writer AI
↓
Reviewer AI
↓
自然文レビュー + 判定JSON
↓
Python側でJSONを抽出・検証
↓
status に応じて処理を分岐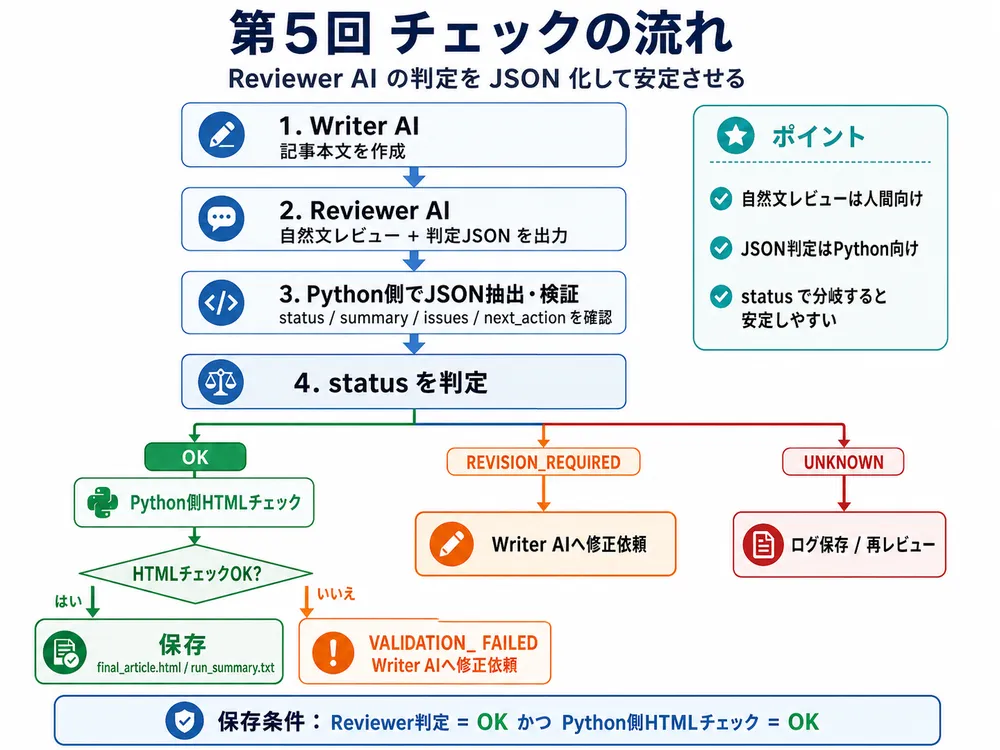
JSONの基本形は、以下のようにします。
{
"status": "OK",
"summary": "記事構成とHTML形式に大きな問題はありません。",
"issues": [],
"next_action": "SAVE"
}修正が必要な場合は、次のようにします。
{
"status": "REVISION_REQUIRED",
"summary": "導入文の結論が弱く、読者に記事の価値が伝わりにくくなっています。",
"issues": [
"導入文の冒頭に結論を追加してください",
"見出しの表現をもう少し具体的にしてください"
],
"next_action": "REVISE"
}Python側HTMLチェックで問題がある場合は、Python側で次のような判定にできます。
{
"status": "VALIDATION_FAILED",
"summary": "HTML形式チェックで問題が見つかりました。",
"issues": [
"Markdownの太字記法が残っています",
"style属性が含まれています"
],
"next_action": "REVISE"
}statusの種類を決める
第5回では、まず以下の4種類に整理します。
| status | 意味 | 次の処理 |
|---|---|---|
OK | Reviewer AIが問題なしと判断 | 保存へ進む |
REVISION_REQUIRED | 内容面で修正が必要 | Writer AIへ戻す |
VALIDATION_FAILED | Python側HTMLチェックでNG | Writer AIへ戻す |
UNKNOWN | JSON不正・判定不能 | ログ保存または再レビュー |
ポイントは、Reviewer AIの自然な表現をそのまま分岐条件にしないことです。
プログラム側では、必ず次のような固定値だけを見ます。
OK
REVISION_REQUIRED
VALIDATION_FAILED
UNKNOWNこうすることで、将来的にイベント駆動型へ進むときも、次のように確実に分岐できるようになります。
OK
↓
article.approved
REVISION_REQUIRED
↓
article.revision_required
VALIDATION_FAILED
↓
article.validation_failed
UNKNOWN
↓
article.review_failed自然文レビューとJSON判定を分ける
Reviewer AIには、完全にJSONだけを返させる方法もあります。
ただし、AI記事作成では、自然文レビューも残した方が分かりやすいといえます。
理由は、人間が見たときに、なぜOKなのか、なぜ修正が必要なのかを確認しやすいからです。
そのため、第5回AI記事作成では次の形式に変更します。
良い点:
- ...
修正点:
- ...
Writer AIへの具体的な修正指示:
- ...
判定JSON:
{
"status": "OK",
"summary": "記事構成とHTML形式に大きな問題はありません。",
"issues": [],
"next_action": "SAVE"
}この形なら、人間にも読みやすく、Python側でも扱いやすくなります。
reviewer.py の考え方
第5回AI記事作成では、reviewer.py のプロンプトを変更します。
これまでは、最後に次のどちらかを書かせていました。
判定:OKまたは、
判定:修正必要第5回AI記事作成では、これをJSONに変えます。
Reviewer AIには、次のように指示します。
最後に必ず「判定JSON:」を出力し、その直後にJSONだけを書いてください。
JSONには status、summary、issues、next_action を含めてください。さらに、JSONの値を制限します。
status は OK または REVISION_REQUIRED のどちらか
next_action は SAVE または REVISE のどちらかこれにより、Reviewer AIが自由に
このまま公開可能
A+
非常に高品質のような判定を出しにくくなります。
Python側でJSONを検証する
JSON化しただけでは、まだ十分ではありません。
LLMは、JSONを少し崩して出力する場合があります。
たとえば、次のような問題が起きる可能性があります。
・JSONの前後に余計な文章が入る
・カンマが抜ける
・statusの値が想定外になる
・issuesが配列ではなく文字列になる
・next_actionが抜けるそのため、Python側でJSONを検証する処理を入れます。
第5回AI記事作成では、新しく review_parser.py のようなファイルを作ると分かりやすいです。
役割は以下です。
review_parser.py
↓
Reviewer AIの出力から判定JSONを取り出す
JSONとして読み込む
必要なキーがあるか確認する
statusの値が許可されたものか確認する
失敗したら UNKNOWN にするreview_parser.py の役割
第5回AI記事作成で追加する review_parser.py は、Reviewer AIの自然文レビューからJSON部分を取り出します。
イメージはこうです。
Reviewer AIの出力
↓
「判定JSON:」以降を抽出
↓
json.loads() で読み込み
↓
status / summary / issues / next_action を検証
↓
Python側で使いやすいdictに変換JSONが壊れていた場合は、次のように扱います。
{
"status": "UNKNOWN",
"summary": "Reviewer AIの判定JSONを解析できませんでした。",
"issues": [
"JSON parse error"
],
"next_action": "RETRY_REVIEW"
}これにより、判定不能な場合もプログラムが止まらず、安全に処理できます。
main.py の分岐も分かりやすくなる
第3回・第4回AI記事作成では、main.py で次のように判定していました。
review_status = get_review_status(latest_review)第5回では、これを次のように変更します。
review_result = parse_review_result(latest_review)
review_status = review_result["status"]そして、分岐は次のようになります。
if review_status == "OK" and not validation_issues:
review_passed = True
break
if validation_issues:
review_for_writer = build_validation_review(validation_issues)
elif review_status == "REVISION_REQUIRED":
review_for_writer = build_review_json_feedback(review_result)
else:
review_for_writer = build_unknown_review_feedback(latest_review)このようにすると、自然文の細かな表現ではなく、JSONの status によって処理を分岐できます。
Python側HTMLチェックとの関係
第5回でも、Python側HTMLチェックは残します。
理由は、Reviewer AIがOKを出しても、HTML形式に問題が残る可能性があるからです。
つまり、保存条件はこれまでと同じです。
Reviewer AIのJSON判定:OK
かつ
Python側HTMLチェック:OKこの2つがそろったときだけ保存します。
逆に、Reviewer AIがOKでも、Python側HTMLチェックがNGなら保存しません。
Reviewer AI:OK
Python側HTMLチェック:NG
↓
VALIDATION_FAILED としてWriter AIへ戻すつまり、第5回では、判定の役割を次のように分けます。
Reviewer AI
→ 内容面の確認
Python側HTMLチェック
→ HTML形式・Markdown混入の確認
JSON
→ エージェント間の安定した受け渡し第5回AI記事作成のファイル構成
第5回AI記事作成では、以下のような構成になります。
article-agent/
├ main.py
├ llm_client.py
├ validators.py
├ review_parser.py
├ agents/
│ ├ planner.py
│ ├ writer.py
│ └ reviewer.py
├ mcp_client.py
├ mcp_server.py
└ output/今回新しく追加するのは、主に以下です。
review_parser.py変更するファイルは、主に以下です。
main.py
validators.py(バグ修正)
agents/reviewer.py第5回AI記事作成 追加・変更ファイル
追加:review_parser.py
import json
import re
from typing import Any
ALLOWED_STATUS = {
"OK",
"REVISION_REQUIRED",
"UNKNOWN",
}
ALLOWED_NEXT_ACTION = {
"SAVE",
"REVISE",
"RETRY_REVIEW",
}
def default_unknown_result(message: str = "Reviewer AIの判定JSONを解析できませんでした。") -> dict:
"""
JSON解析に失敗した場合や、形式が不正な場合に返す標準結果。
"""
return {
"status": "UNKNOWN",
"summary": message,
"issues": [message],
"next_action": "RETRY_REVIEW",
}
def extract_json_block(review_text: str) -> str | None:
"""
Reviewer AIの出力から「判定JSON:」以降のJSON部分を抽出する。
想定形式:
判定JSON:
{
"status": "OK",
"summary": "...",
"issues": [],
"next_action": "SAVE"
}
"""
marker_patterns = [
"判定JSON:",
"判定JSON:",
"判定 JSON:",
"判定 JSON:",
]
start_index = -1
for marker in marker_patterns:
index = review_text.find(marker)
if index != -1:
start_index = index + len(marker)
break
if start_index == -1:
return None
after_marker = review_text[start_index:].strip()
# ```json や ``` が混ざった場合に備えて除去
after_marker = after_marker.replace("```json", "")
after_marker = after_marker.replace("```JSON", "")
after_marker = after_marker.replace("```", "")
after_marker = after_marker.strip()
# 最初の { から最後の } までを抽出
first_brace = after_marker.find("{")
last_brace = after_marker.rfind("}")
if first_brace == -1 or last_brace == -1 or last_brace <= first_brace:
return None
return after_marker[first_brace : last_brace + 1]
def normalize_review_result(data: dict[str, Any]) -> dict:
"""
JSONから読み込んだdictを、プログラムで扱いやすい形式に正規化する。
"""
status = data.get("status", "UNKNOWN")
summary = data.get("summary", "")
issues = data.get("issues", [])
next_action = data.get("next_action", "")
if not isinstance(status, str):
status = "UNKNOWN"
status = status.strip()
if status not in ALLOWED_STATUS:
return default_unknown_result(f"statusの値が不正です: {status}")
if not isinstance(summary, str):
summary = str(summary)
if not isinstance(issues, list):
issues = [str(issues)]
normalized_issues = []
for issue in issues:
if isinstance(issue, str):
normalized_issues.append(issue)
else:
normalized_issues.append(str(issue))
if not isinstance(next_action, str):
next_action = ""
next_action = next_action.strip()
# statusに応じて next_action を補完・補正
if status == "OK":
next_action = "SAVE"
elif status == "REVISION_REQUIRED":
next_action = "REVISE"
elif status == "UNKNOWN":
next_action = "RETRY_REVIEW"
if next_action not in ALLOWED_NEXT_ACTION:
return default_unknown_result(f"next_actionの値が不正です: {next_action}")
return {
"status": status,
"summary": summary,
"issues": normalized_issues,
"next_action": next_action,
}
def parse_review_result(review_text: str) -> dict:
"""
Reviewer AIの自然文レビューから判定JSONを抽出・検証する。
戻り値の例:
{
"status": "OK",
"summary": "記事構成とHTML形式に大きな問題はありません。",
"issues": [],
"next_action": "SAVE"
}
"""
json_block = extract_json_block(review_text)
if json_block is None:
return default_unknown_result("判定JSONが見つかりませんでした。")
try:
data = json.loads(json_block)
except json.JSONDecodeError as error:
return default_unknown_result(f"JSONの解析に失敗しました: {error}")
if not isinstance(data, dict):
return default_unknown_result("判定JSONの形式がオブジェクトではありません。")
return normalize_review_result(data)
def review_result_to_text(review_result: dict) -> str:
"""
review_resultを保存用のJSON文字列に変換する。
"""
return json.dumps(review_result, ensure_ascii=False, indent=2)
def build_review_json_feedback(review_result: dict) -> str:
"""
Reviewer AIのJSON判定をWriter AIへ渡す修正指示テキストに変換する。
"""
status = review_result.get("status", "UNKNOWN")
summary = review_result.get("summary", "")
issues = review_result.get("issues", [])
issue_text = "\n".join(f"- {issue}" for issue in issues) if issues else "- 具体的な修正点はありません。"
return f"""
Reviewer AIの判定JSONに基づく修正指示です。
status:
{status}
summary:
{summary}
issues:
{issue_text}
Writer AIへの修正指示:
・上記のissuesを反映してください。
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
"""
def build_unknown_review_feedback(review_text: str, review_result: dict) -> str:
"""
判定JSONがUNKNOWNになった場合に、Writer AIへ渡す安全な修正指示を作成する。
"""
summary = review_result.get("summary", "判定JSONを解析できませんでした。")
issues = review_result.get("issues", [])
issue_text = "\n".join(f"- {issue}" for issue in issues) if issues else "- 判定JSONの形式が不明です。"
return f"""
Reviewer AIの判定JSONを正しく解析できませんでした。
理由:
{summary}
issues:
{issue_text}
Reviewer AIの元出力:
{review_text}
Writer AIへの修正指示:
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
"""変更:agents/reviewer.py
from llm_client import call_gemma4
def run_reviewer(keyword: str, draft: str) -> str:
"""
Reviewer AI:
Writer AIが作成した記事を確認し、自然文レビューと判定JSONを返す。
"""
system_prompt = """
あなたは記事品質を確認するReviewer AIです。
記事を読み、SEO・読みやすさ・誤字脱字・過剰表現・構成・HTML形式の観点で確認してください。
重要:
・自然文レビューは人間が読むための説明です。
・プログラムが処理するために、最後に必ず「判定JSON:」を出力してください。
・「判定JSON:」の直後には、JSONのみを出力してください。
・JSONの前後にコードブロック記号 ``` を使わないでください。
・JSONには必ず status、summary、issues、next_action を含めてください。
・status は必ず "OK" または "REVISION_REQUIRED" のどちらかにしてください。
・next_action は必ず "SAVE" または "REVISE" のどちらかにしてください。
・issues は必ず配列にしてください。
・判定JSON内にコメントを書かないでください。
・判定JSON内に絵文字、星評価、曖昧な評価表現を入れないでください。
"""
user_prompt = f"""
以下の記事をレビューしてください。
キーワード:
{keyword}
記事:
{draft}
確認項目:
1. 検索意図に合っているか
2. 見出しと本文が一致しているか
3. 誤字脱字がないか
4. 過剰な断定表現がないか
5. AI要約ブロックが分かりやすいか
6. FAQが本文と矛盾していないか
7. styleタグ、CSS、JavaScriptが含まれていないか
8. Markdown記法が混ざっていないか
9. バッククォート3つのコードブロック記号が含まれていないか
10. HTMLタグの構造が崩れていないか
11. h2 / h3 / p / ul / li などで整理されているか
12. 根拠のない最新情報を断定していないか
出力形式:
良い点:
- ...
修正点:
- ...
Writer AIへの具体的な修正指示:
- ...
判定JSON:
{{
"status": "OK",
"summary": "記事構成、内容、HTML形式に大きな問題はありません。",
"issues": [],
"next_action": "SAVE"
}}
または、修正が必要な場合:
判定JSON:
{{
"status": "REVISION_REQUIRED",
"summary": "修正が必要な理由を1文で説明してください。",
"issues": [
"修正点1",
"修正点2"
],
"next_action": "REVISE"
}}
重要:
・最後は必ず「判定JSON:」とJSONで終えてください。
・判定JSONの後には何も書かないでください。
・JSONは必ず正しいJSON形式にしてください。
・statusに "このまま公開可能"、"A+"、"高品質" などは使わないでください。
"""
return call_gemma4(system_prompt, user_prompt)変更:main.py
from datetime import datetime
import re
from agents.planner import run_planner
from agents.writer import run_writer
from agents.reviewer import run_reviewer
from mcp_client import save_text_file, save_article, save_run_summary
from validators import validate_html_fragment, sanitize_html_fragment
from review_parser import (
parse_review_result,
review_result_to_text,
build_review_json_feedback,
build_unknown_review_feedback,
)
MAX_REVIEW_LOOPS = 3
def slugify_keyword(keyword: str) -> str:
"""
フォルダ名に使いやすいようにキーワードを簡易変換する。
日本語はそのまま残し、使いにくい記号だけ置き換える。
"""
slug = keyword.strip()
slug = re.sub(r"\s+", "_", slug)
slug = re.sub(r'[\\/:*?"<>|]', "_", slug)
if not slug:
slug = "article"
return slug[:40]
def build_validation_text(issues: list[str]) -> str:
"""
Python側チェック結果を保存用テキストに変換する。
"""
if not issues:
return "Python側HTMLチェック:OK\n"
lines = [
"Python側HTMLチェック:修正必要",
"",
]
for issue in issues:
lines.append(f"- {issue}")
return "\n".join(lines)
def build_validation_review(issues: list[str]) -> str:
"""
Python側チェックで見つかった問題を、
Writer AIに渡せるレビュー文に変換する。
"""
issue_text = "\n".join(f"- {issue}" for issue in issues)
return f"""
Python側のHTML形式チェックで、以下の問題が見つかりました。
{issue_text}
Writer AIへの修正指示:
・上記の問題をすべて修正してください。
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
status:
VALIDATION_FAILED
"""
def main():
print("Gemma 4ローカル・マルチエージェント記事作成システム")
print("-" * 50)
keyword = input("記事キーワードを入力してください: ").strip()
if not keyword:
print("キーワードが入力されていません。終了します。")
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
keyword_slug = slugify_keyword(keyword)
run_dir = f"output/{timestamp}_{keyword_slug}"
print(f"\n実行結果フォルダ: {run_dir}")
print("\n[1] Planner AI が記事設計を作成中...")
plan = run_planner(keyword)
save_text_file(f"{run_dir}/plan.txt", plan)
print("\n[2] Writer AI が初稿を作成中...")
article = run_writer(keyword=keyword, plan=plan)
article = sanitize_html_fragment(article)
save_text_file(f"{run_dir}/draft_1.html", article)
latest_review = ""
latest_review_result = {
"status": "UNKNOWN",
"summary": "まだレビューは実行されていません。",
"issues": [],
"next_action": "RETRY_REVIEW",
}
review_passed = False
final_review_status = "UNKNOWN"
final_validation_issues: list[str] = []
for loop_count in range(1, MAX_REVIEW_LOOPS + 1):
print(f"\n[3] Reviewer AI がレビュー中... ({loop_count}/{MAX_REVIEW_LOOPS})")
latest_review = run_reviewer(keyword=keyword, draft=article)
# 自然文レビュー全文を保存
save_text_file(f"{run_dir}/review_{loop_count}.txt", latest_review)
print("\n--- Reviewer AI のレビュー結果 ---")
print(latest_review)
print("--- レビュー結果ここまで ---")
# 第5回:判定JSONを抽出・検証
latest_review_result = parse_review_result(latest_review)
final_review_status = latest_review_result["status"]
# JSON判定だけを別ファイルとして保存
save_text_file(
f"{run_dir}/review_result_{loop_count}.json",
review_result_to_text(latest_review_result),
)
print("\n--- Reviewer AI の判定JSON ---")
print(review_result_to_text(latest_review_result))
print("--- 判定JSONここまで ---")
if final_review_status == "UNKNOWN":
print("\nReviewer AI の判定JSONが不明です。修正必要として扱います。")
# 保存前・検証前に自動整形する
article = sanitize_html_fragment(article)
validation_issues = validate_html_fragment(article)
final_validation_issues = validation_issues
validation_text = build_validation_text(validation_issues)
save_text_file(f"{run_dir}/validation_{loop_count}.txt", validation_text)
if validation_issues:
print("\nPython側HTMLチェック:修正必要")
for issue in validation_issues:
print(f"- {issue}")
# 保存条件:
# Reviewer AIのJSON判定がOK
# かつ Python側HTMLチェックもOK
if final_review_status == "OK" and not validation_issues:
print("\nReviewer AI JSON判定 + Python側HTMLチェック の判定:OK")
review_passed = True
break
print("\n判定:修正必要")
# 最大回数に達した場合は、未検証の修正版を作らず終了
if loop_count == MAX_REVIEW_LOOPS:
print("\n最大レビュー回数に達しました。これ以上修正せず、最後に検証済みの記事を保存します。")
break
if validation_issues:
review_for_writer = build_validation_review(validation_issues)
elif final_review_status == "REVISION_REQUIRED":
review_for_writer = build_review_json_feedback(latest_review_result)
else:
review_for_writer = build_unknown_review_feedback(latest_review, latest_review_result)
print(f"\n[4] Writer AI がレビュー指摘に従って修正中... ({loop_count}/{MAX_REVIEW_LOOPS})")
article = run_writer(
keyword=keyword,
plan=plan,
review=review_for_writer,
previous_draft=article,
)
article = sanitize_html_fragment(article)
next_draft_number = loop_count + 1
save_text_file(f"{run_dir}/draft_{next_draft_number}.html", article)
print("\n[5] 最終HTMLを保存中...")
article = sanitize_html_fragment(article)
result = save_article(run_dir, article)
status_text = "OK判定後に保存" if review_passed else "最大レビュー回数到達後に保存"
if final_validation_issues:
validation_summary = "\n".join(f"- {issue}" for issue in final_validation_issues)
else:
validation_summary = "Python側HTMLチェック:OK"
review_json_summary = review_result_to_text(latest_review_result)
summary = f"""実行キーワード:{keyword}
保存状態:{status_text}
Reviewer最終JSON判定:{final_review_status}
最終保存先:{result['path']}
レビュー最大回数:{MAX_REVIEW_LOOPS}
実行結果フォルダ:{run_dir}
最終Reviewer判定JSON:
{review_json_summary}
最終Python側HTMLチェック:
{validation_summary}
"""
save_run_summary(run_dir, summary)
print("\n完了しました。")
print(f"保存先: {result['path']}")
if review_passed:
print("保存状態:Reviewer AI のJSON判定とPython側HTMLチェックのOK後に保存しました。")
else:
print("保存状態:最大レビュー回数に達したため、最後の記事を保存しました。")
print(f"Reviewer最終JSON判定:{final_review_status}")
if __name__ == "__main__":
main()validators.py(バグ修正)
import re
def convert_markdown_bold_to_strong(text: str) -> str:
"""
Markdownの **強調** を <strong>強調</strong> に変換する。
"""
return re.sub(
r"\*\*(.+?)\*\*",
r"<strong>\1</strong>",
text,
flags=re.DOTALL,
)
def convert_markdown_headings_to_html(text: str) -> str:
"""
Markdown見出しをHTML見出しに変換する。
例:
## 見出し → <h2>見出し</h2>
### 見出し → <h3>見出し</h3>
#### 見出し → <h4>見出し</h4>
"""
# h4から先に変換する
text = re.sub(
r"^\s*####\s+(.+?)\s*$",
r"<h4>\1</h4>",
text,
flags=re.MULTILINE,
)
text = re.sub(
r"^\s*###\s+(.+?)\s*$",
r"<h3>\1</h3>",
text,
flags=re.MULTILINE,
)
text = re.sub(
r"^\s*##\s+(.+?)\s*$",
r"<h2>\1</h2>",
text,
flags=re.MULTILINE,
)
return text
def convert_markdown_lists_to_html(text: str) -> str:
"""
Markdownの箇条書きをHTMLのul/liに変換する。
対応例:
* 項目
- 項目
"""
lines = text.splitlines()
converted_lines = []
list_items = []
def flush_list():
nonlocal list_items
if list_items:
converted_lines.append("<ul>")
for item in list_items:
converted_lines.append(f" <li>{item}</li>")
converted_lines.append("</ul>")
list_items = []
for line in lines:
stripped = line.strip()
match = re.match(r"^[*-]\s+(.+)$", stripped)
if match:
list_items.append(match.group(1).strip())
else:
flush_list()
converted_lines.append(line)
flush_list()
return "\n".join(converted_lines)
def strip_code_fences(text: str) -> str:
"""
LLMが誤って出力するコードブロック記号を取り除く。
"""
text = text.replace("```html", "")
text = text.replace("```HTML", "")
text = text.replace("```json", "")
text = text.replace("```JSON", "")
text = text.replace("```", "")
return text.strip()
def remove_style_and_script_blocks(text: str) -> str:
"""
<style>...</style> と <script>...</script> を削除する。
"""
text = re.sub(
r"<\s*style\b[^>]*>.*?<\s*/\s*style\s*>",
"",
text,
flags=re.IGNORECASE | re.DOTALL,
)
text = re.sub(
r"<\s*script\b[^>]*>.*?<\s*/\s*script\s*>",
"",
text,
flags=re.IGNORECASE | re.DOTALL,
)
return text
def remove_inline_style_attributes(text: str) -> str:
"""
style="..." または style='...' を削除する。
"""
text = re.sub(
r"\sstyle\s*=\s*\"[^\"]*\"",
"",
text,
flags=re.IGNORECASE,
)
text = re.sub(
r"\sstyle\s*=\s*'[^']*'",
"",
text,
flags=re.IGNORECASE,
)
return text
def normalize_line_break_tags(text: str) -> str:
"""
不正または不要な改行タグを整理する。
</br> はHTMLとして不自然なので削除する。
<br/> や <br /> は <br> に統一する。
"""
text = re.sub(r"<\s*/\s*br\s*>", "", text, flags=re.IGNORECASE)
text = re.sub(r"<\s*br\s*/\s*>", "<br>", text, flags=re.IGNORECASE)
text = re.sub(r"<\s*br\s*>", "<br>", text, flags=re.IGNORECASE)
return text
def extract_body_content_if_needed(text: str) -> str:
"""
LLMが <!DOCTYPE html> / html / head / body 付きで出力した場合、
body内の内容だけを取り出す。
bodyタグがない場合は、html/head/body系タグを削除する。
"""
body_match = re.search(
r"<\s*body\b[^>]*>(.*?)<\s*/\s*body\s*>",
text,
flags=re.IGNORECASE | re.DOTALL,
)
if body_match:
return body_match.group(1).strip()
text = re.sub(r"<!DOCTYPE[^>]*>", "", text, flags=re.IGNORECASE)
text = re.sub(r"<\s*/?\s*html\b[^>]*>", "", text, flags=re.IGNORECASE)
text = re.sub(
r"<\s*head\b[^>]*>.*?<\s*/\s*head\s*>",
"",
text,
flags=re.IGNORECASE | re.DOTALL,
)
text = re.sub(r"<\s*/?\s*body\b[^>]*>", "", text, flags=re.IGNORECASE)
return text.strip()
def sanitize_html_fragment(article: str) -> str:
"""
Writer AIの出力を保存前に軽く自動整形する。
目的:
・Markdownの ** を <strong> に変換
・Markdown見出しを h2 / h3 / h4 に変換
・Markdown箇条書きを ul / li に変換
・コードブロック記号を削除
・style/scriptタグを削除
・インラインstyle属性を削除
・html/head/body付きの場合は本文断片に近づける
・不正な </br> を削除する
"""
cleaned = article
cleaned = strip_code_fences(cleaned)
cleaned = extract_body_content_if_needed(cleaned)
cleaned = remove_style_and_script_blocks(cleaned)
cleaned = remove_inline_style_attributes(cleaned)
cleaned = normalize_line_break_tags(cleaned)
cleaned = convert_markdown_headings_to_html(cleaned)
cleaned = convert_markdown_lists_to_html(cleaned)
cleaned = convert_markdown_bold_to_strong(cleaned)
return cleaned.strip()
def validate_html_fragment(article: str) -> list[str]:
"""
Writer AIの出力をPython側で機械的にチェックする。
問題がなければ空のリストを返す。
"""
issues = []
forbidden_patterns = {
"styleタグが含まれています。<style>...</style> は出力しないでください。": r"<\s*style\b",
"インラインCSSが含まれています。style属性は使わないでください。": r"\sstyle\s*=",
"scriptタグが含まれています。JavaScriptは出力しないでください。": r"<\s*script\b",
"Markdownのコードブロック記号が含まれています。": r"```",
"Markdownの太字記法 ** が含まれています。HTMLのstrongタグに変換してください。": r"\*\*",
"Markdown見出し記法 ## が含まれています。h2/h3タグに変換してください。": r"^\s*#{2,6}\s+",
"Markdown箇条書き記法が含まれています。ul/liタグに変換してください。": r"^\s*[*-]\s+",
"不正な </br> タグが含まれています。削除または <br> に修正してください。": r"<\s*/\s*br\s*>",
"htmlタグが含まれています。HTML断片として出力してください。": r"<\s*html\b",
"headタグが含まれています。HTML断片として出力してください。": r"<\s*head\b",
"bodyタグが含まれています。HTML断片として出力してください。": r"<\s*body\b",
}
for message, pattern in forbidden_patterns.items():
if re.search(pattern, article, flags=re.IGNORECASE | re.MULTILINE):
issues.append(message)
placeholder_phrases = [
"(コンテンツ本文ここに挿入)",
"ここに本文を挿入",
"ここに挿入",
"以下略",
"省略",
]
for phrase in placeholder_phrases:
if phrase in article:
issues.append(
"本文がプレースホルダーまたは省略表現になっています。記事全文を出力してください。"
)
break
if "<h2" not in article:
issues.append("h2タグが見つかりません。記事本文にh2見出しを含めてください。")
if "<p" not in article:
issues.append("pタグが見つかりません。本文はpタグで記述してください。")
return issues第5回AI記事作成 実行結果
ターミナル出力
(UTF-8)
(SHIFT-JIS)
作成記事
(UTF-8)
(SHIFT-JIS)
第5回AI記事作成で保存されるファイル
第5回でも、途中保存の仕組みは維持します。
たとえば、以下のようなファイルを保存します。
plan.txt
draft_1.html
review_1.txt
review_result_1.json
validation_1.txt
draft_2.html
review_2.txt
review_result_2.json
validation_2.txt
final_article.html
run_summary.txtポイントは、自然文レビューとは別に、JSON判定も保存することです。
review_1.txt
→ Reviewer AIの自然文レビュー全文
review_result_1.json
→ Pythonが処理するための判定JSONこのように分けると、あとから確認するときも分かりやすくなります。
今後のイベント駆動型へのつながり
第5回でJSON化する理由は、単に判定を安定させるためだけではありません。
今後、イベント駆動型マルチエージェントへ進むための準備でもあります。
イベント駆動型では、AIの出力をもとに次のイベントを発火します。
review_result.status == "OK"
↓
article.approved
review_result.status == "REVISION_REQUIRED"
↓
article.revision_required
validation.status == "VALIDATION_FAILED"
↓
article.validation_failedこのとき、自然文のレビューをそのままイベント分岐に使うのは危険です。
しかし、JSONの status であれば、イベント分岐がしやすくなります。
つまり、第5回は、後のイベント駆動型マルチエージェントに進むための重要な土台です。
まとめ:AIエージェント間の受け渡しはJSON化すると安定する
第5回では、Reviewer AIの判定結果をJSON形式で受け渡す構成に改善しました。
第3回・第4回では、Reviewer AIの自然文レビューから 判定:OK や 判定:修正必要 を読み取っていました。
しかし、LLMの自然文出力は揺れます。
そこで第5回では、自然文レビューは人間が読むために残し、Pythonが処理する判定結果はJSONとして分離します。
自然文レビュー
→ 人間が読む
JSON判定
→ Pythonが処理するこの分離により、AI記事作成システムはさらに安定します。
特に、将来的にイベント駆動型へ進む場合、status による明確な分岐は重要です。
第5回は、AIマルチエージェント記事作成システムを、単なる順番実行から、安定したエージェント間連携へ進めるための回です。
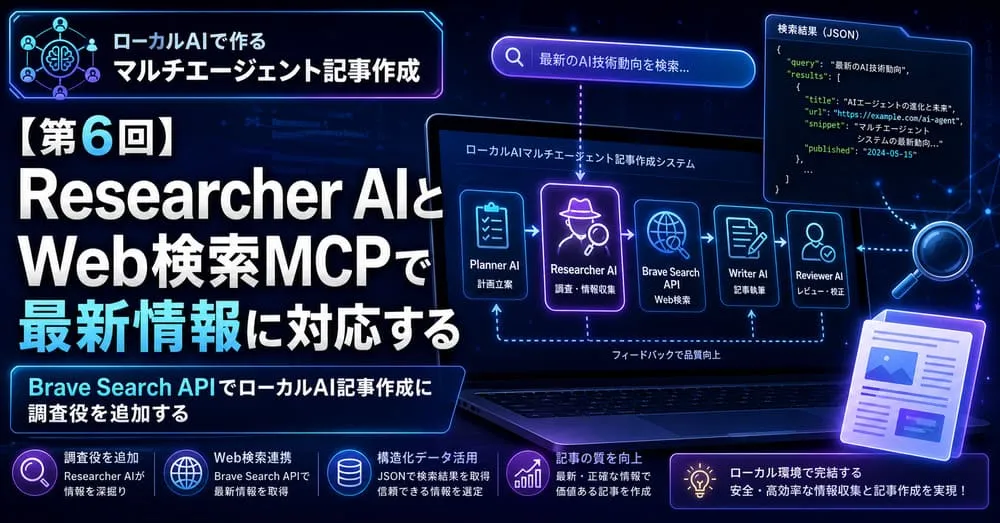
第6回では、Planner AI、Writer AI、Reviewer AIに加えて、調査役となるResearcher AIを追加します。