AIマルチエージェントによる記事作成では、完成した記事だけを見ても、どの工程で問題が発生したのか判断が難しいという課題があります。
第3回では、この課題を解決するため、各AI(Planner・Writer・Reviewer)の出力を段階的に保存し、レビュー結果やHTMLチェック結果もファイルとして記録することで、失敗の原因を特定しやすくしました。
さらに、Python側で品質チェック機能を強化しました。
具体的には、Markdown記法の崩れやCSS混入を自動で検出・修正し、Reviewer AIとPythonチェックの両方をクリアした記事だけを最終保存する仕組みを構築しています。
この二段階チェック体制により、記事品質の安定化と問題発生時の迅速な原因究明が可能になります。
AI記事作成(第2回)で見えた課題
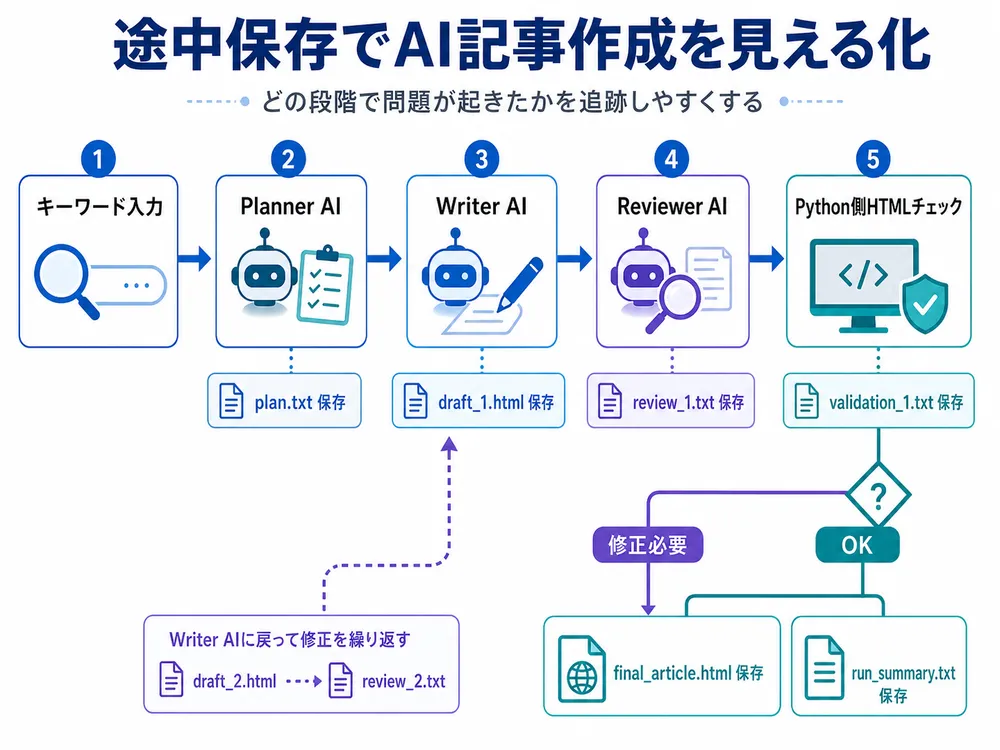
第2回では、Planner AI、Writer AI、Reviewer AIの役割を整理し、Writer AIとReviewer AIをループさせる構成に改善しました。
基本の流れは以下の通りです。
キーワード入力
↓
Planner AI
↓
Writer AI
↓
Reviewer AI
├ OK → 保存
└ 修正必要 → Writer AIへ戻すこの仕組みによって、単純な一方向の処理ではなく、Reviewer AIの指摘をWriter AIに戻して記事を改善する流れを作れました。
しかし、実際に動かしてみると、次のような課題が見つかりました。
・Reviewer AIの判定形式が安定しない
・「判定:OK」と出る場合もあれば、別の表現になる場合がある
・HTMLにMarkdown記法が混ざる
・styleタグやインラインCSSが残る場合がある
・最終記事だけでは、どの段階で問題が起きたか分かりにくいそこで第3回では、記事作成の途中結果を保存しながら、どのAIが、どの段階で、どのような出力をしたのか確認できるようにします。
第3回での作成ファイル
第3回では、1回の実行ごとに専用フォルダを作成し、その中に途中結果を保存します。
たとえば、キーワードが「ブロックチェーン」の場合、以下のようなフォルダ構成になります。
output/
└ 20260430_172544_ブロックチェーン/
├ plan.txt
├ draft_1.html
├ draft_2.html
├ review_1.txt
├ review_2.txt
├ validation_1.txt
├ validation_2.txt
├ final_article.html
└ run_summary.txtこのように保存しておくことで、次の確認ができます。
plan.txt
→ Planner AIの記事設計
draft_1.html
→ Writer AIの初稿
review_1.txt
→ Reviewer AIの1回目レビュー
validation_1.txt
→ Python側HTMLチェックの1回目結果
draft_2.html
→ Writer AIの修正版
review_2.txt
→ Reviewer AIの2回目レビュー
validation_2.txt
→ Python側HTMLチェックの2回目結果
final_article.html
→ 最終保存された記事
run_summary.txt
→ 実行全体の結果つまり、第3回の目的は、単に記事を生成することではありません。
AI記事作成プロセスにおける失敗原因を可視化し、出力品質を安定させることが狙いです。
途中保存が必要な理由
AIマルチエージェントでは、複数のAIが順番に出力を渡し合います。
Planner AI
↓
Writer AI
↓
Reviewer AI
↓
Writer AI
↓
Reviewer AIこの流れでは、最終記事だけを見ても、どこで出力が崩れたのか分かりません。
たとえば、最終記事にMarkdown記法が残っていた場合、原因はいくつか考えられます。
・Writer AIが初稿でMarkdownを出した
・Reviewer AIがMarkdown混入を見逃した
・Writer AIが修正時にMarkdownを追加した
・Python側で検出していなかった途中結果を保存していれば、原因を段階ごとに確認できます。
draft_1.html に問題がある
→ 初稿の時点でWriter AIが崩している
review_1.txt で指摘されていない
→ Reviewer AIが見逃している
validation_1.txt で検出されている
→ Python側チェックが機能している
draft_2.html で修正されている
→ Writer AIまたはPython側整形が効いているこのように、途中保存はAIマルチエージェントのデバッグに欠かせない仕組みといえます。
今回の改善ポイント
第3回では、主に以下の3つを改善しました。
1. Reviewer AIの判定形式を読み取れるようにする
2. Python側でHTMLを自動整形する
3. Python側HTMLチェックを通過した記事だけを保存する次から、それぞれの処理を解説します。
改善1:Reviewer AIの判定形式を読み取る
第2回までの課題の一つは、Reviewer AIの判定形式が安定しないことでした。
本来は、
判定:OK
または、
判定:修正必要
のどちらかだけを出してほしいところです。
しかし、実際には次のように、判定:の後ろに改行が入ったり・判定結果が文字列で出力される場合がありました。
判定:
OK
判定:A+ (非常に高品質。軽微な構造的修正のみ推奨)
判定:⭐️⭐️⭐️⭐️⭐️ (5/5)
この場合、人間にはレビュー結果が正常だと分かりますが、プログラム側ではレビュー結果が正常と判断できない可能性があります。
そこで main.py では、get_review_status() を使い、判定OKの出力を、次の両方に対応できるようにしました。
判定:OK
判定:
OK
さらに、判定が文字列で出力される場合の対応として、形式不明の出力を用意しました。
main.py では、Reviewer AIの出力から判定行を探し、OK、修正必要、UNKNOWN のいずれかとして扱うようにしています。
これにより、Reviewer AIの出力が多少揺れても、プログラム側で判定を読み取りやすくなりました。
改善2:Reviewer AIの判定出力を厳格化する
reviewer.py 側でも、判定出力を安定させるためにプロンプトを調整しました。
Reviewer AIには、最後の判定を必ず以下のどちらかだけにするよう指示しています。
判定:OKまたは、
判定:修正必要さらに、判定行には以下を入れないようにしました。
・絵文字
・星評価
・補足説明
・英語コメント
・「このまま公開可能」などの曖昧な表現これと同時に、判定行を最後に1回だけ出力するように指示を加えました。
これにより、AIの自然な文章評価を、プログラムが処理しやすい形式としました。
改善3:Python側でHTMLを自動整形する
AIに「HTMLだけで出力してください」と指示しても、実際には次のようなものが混ざることがあります。
・Markdownの **太字**
・コードブロック記号
・styleタグ
・scriptタグ
・インラインCSS
・html / head / body タグそこで validators.py に、HTMLを自動整形する sanitize_html_fragment() を追加しました。
主な処理は以下です。
・Markdownの **強調** を <strong>強調</strong> に変換
・コードブロック記号を削除
・styleタグとscriptタグを削除
・style属性を削除
・html/head/body付きの場合は本文部分だけを抽出validators.py には、Markdown太字記法を <strong> に変換する処理、styleタグやscriptタグを削除する処理、HTML文書全体が出てしまった場合に本文断片へ近づける処理が含まれています。
これにより、Writer AIが多少ルールを外しても、Python側で一定程度補正できるようにしています。
改善4:Python側HTMLチェックを追加する
自動整形した後も、最終的に問題が残っていないか確認する必要があります。
そこで、validate_html_fragment() で以下をチェックします。
・styleタグが残っていないか
・インラインCSSが残っていないか
・scriptタグが残っていないか
・Markdown記法が残っていないか
・html/head/bodyタグが残っていないか
・プレースホルダーが残っていないか
・h2タグがあるか
・pタグがあるかこのPython側チェックにより、Reviewer AIが見逃した形式上の問題も検出できるようになりました。
今回の実行結果
今回の作業では、「ブロックチェーン」というキーワードを使って記事を自動生成しました。
プログラムの動作確認と改善のため、合計3回のテストを実施しています。
各回の実行結果(ターミナル出力)は以下の通りです。
第1回目テスト結果(utf-8)
第2回目テスト結果(utf-8)
第3回目テスト結果(utf-8)
第1回目、第2回目テストでは、判定:OKが正常に出力されず、最大レビュー回数に達して終了しています。
第3回目テストの2回目のレビュー処理で、判定:OKが正常な形式で出力されReviewer AI + Python側HTMLチェック の判定:OKとなり、レビューが完了した記事が出力されました。
第3回目テストでの run_summary.txt (実行全体の結果)では、以下のように記録されています。
保存状態:OK判定後に保存
Reviewer最終判定:OK
最終Python側HTMLチェック:OK第3回目テスト run_summary.txt(utf-8)
第3回目テスト run_summary.txt(Shift JIS)
第3回目テスト完成記事(utf-8)
第3回目テスト完成記事(Shift-JIS)
修正後のプログラム
以下は、第3回のファイル構成と使用プログラム一式です。
ファイル構成
article-agent
├─ agents
│ ├── planner.py
│ ├── reviewer.py
│ └── writer.py
├── llm_client.py
├── main.py
├── mcp_client.py
├── mcp_server.py
└── validators.py
使用プログラム一式
planner.py
from llm_client import call_gemma4
def run_planner(keyword: str) -> str:
"""
Planner AI:
キーワードから記事設計を作成する。
"""
system_prompt = """
あなたは記事設計を担当するPlanner AIです。
入力されたキーワードをもとに、SEO記事の設計を行ってください。
本文は書かず、Writer AIが記事を書きやすいように設計情報を整理してください。
出力は日本語で、分かりやすく整理してください。
"""
user_prompt = f"""
以下のキーワードで記事設計を作成してください。
キーワード:
{keyword}
必ず含める項目:
1. 想定読者
2. 検索意図
3. 記事目的
4. SEOタイトル案
5. h2/h3構成
6. 執筆時の注意点
7. Writer AIへの指示
注意:
・本文はまだ書かないでください。
・Writer AIが迷わないように、構成と方針を明確にしてください。
"""
return call_gemma4(system_prompt, user_prompt)reviewer.py
from llm_client import call_gemma4
def run_reviewer(keyword: str, draft: str) -> str:
"""
Reviewer AI:
Writer AIが作成した記事を確認し、OKまたは修正必要を判定する。
"""
system_prompt = """
あなたは記事品質を確認するReviewer AIです。
記事を読み、SEO・読みやすさ・誤字脱字・過剰表現・構成・HTML形式の観点で確認してください。
重要:
・問題があれば、Writer AIが修正しやすいように具体的に指摘してください。
・問題がなければ、最後に必ず「判定:OK」と書いてください。
・修正が必要な場合は、最後に必ず「判定:修正必要」と書いてください。
・最後の判定は、必ず次のどちらかだけにしてください。
判定:OK
判定:修正必要
・判定行に絵文字、星評価、補足説明、英語コメントを追加しないでください。
・「このまま公開可能」「非常に高いレベル」「Minor improvement suggested」などは判定行に書かないでください。
・判定行は最後に1回だけ出力してください。
"""
user_prompt = f"""
以下の記事をレビューしてください。
キーワード:
{keyword}
記事:
{draft}
確認項目:
1. 検索意図に合っているか
2. 見出しと本文が一致しているか
3. 誤字脱字がないか
4. 過剰な断定表現がないか
5. AI要約ブロックが分かりやすいか
6. FAQが本文と矛盾していないか
7. styleタグ、CSS、JavaScriptが含まれていないか
8. Markdown記法が混ざっていないか
9. バッククォート3つのコードブロック記号が含まれていないか
10. HTMLタグの構造が崩れていないか
11. h2 / h3 / p / ul / li などで整理されているか
12. 根拠のない最新情報を断定していないか
出力形式:
良い点:
- ...
修正点:
- ...
Writer AIへの具体的な修正指示:
- ...
判定:
OK または 修正必要
重要:
最後の行は、必ず次のどちらか一行だけにしてください。
判定:OK
または
判定:修正必要
"""
return call_gemma4(system_prompt, user_prompt)writer.py
from llm_client import call_gemma4
def run_writer(
keyword: str,
plan: str,
review: str | None = None,
previous_draft: str | None = None,
) -> str:
"""
Writer AI:
Planner AIの設計に沿って記事を作成する。
Reviewer AIまたはPython側チェックの指摘がある場合は、前回の記事を修正する。
"""
system_prompt = """
あなたはSEO記事を作成するWriter AIです。
Planner AIの設計に沿って、読みやすく分かりやすい日本語記事をHTML形式で作成してください。
重要な出力ルール:
・HTML断片として出力する
・html、head、bodyタグは出力しない
・styleタグ、CSS、JavaScriptは出力しない
・Markdown記法は使わない
・コードブロック記号 ``` は出力しない
・見出しは h2 / h3 を使う
・本文は p タグを使う
・箇条書きは ul / li を使う
・表が必要な場合は table / tr / th / td を使う
・誇張表現を避ける
・初心者にも理解しやすい文章にする
・根拠のない最新情報や未確認情報は断定しない
・本文を省略しない
・「ここに挿入」「省略」「以下略」などのプレースホルダーを使わない
"""
if review and previous_draft:
user_prompt = f"""
以下の記事を、Reviewer AIまたはPython側チェックの指摘に従って修正してください。
キーワード:
{keyword}
記事設計:
{plan}
修正前の記事:
{previous_draft}
修正指示:
{review}
修正条件:
・修正前の記事本文を維持しながら、必要な箇所だけ改善する
・記事本文を削除しない
・記事本文をプレースホルダーに置き換えない
・「ここに挿入」「省略」「以下略」などを使わない
・必ず修正後の記事全文を出力する
・前回の記事の本文量を大きく減らさない
・HTML断片として出力する
・html、head、bodyタグは出力しない
・styleタグ、CSS、JavaScriptは出力しない
・Markdown記法は使わない
・コードブロック記号 ``` は出力しない
・h2 / h3 / p / ul / li / table などのHTMLタグで整理する
・SEOタイトル、メタディスクリプション、AI要約ブロック、本文、FAQ、まとめを含める
"""
else:
user_prompt = f"""
以下の記事設計をもとに、SEO記事をHTML形式で作成してください。
キーワード:
{keyword}
記事設計:
{plan}
出力条件:
・HTML断片として出力する
・html、head、bodyタグは出力しない
・styleタグ、CSS、JavaScriptは出力しない
・Markdown記法は使わない
・コードブロック記号 ``` は出力しない
・SEOタイトルを含める
・メタディスクリプションを含める
・AI要約ブロックを含める
・h2/h3構成に沿った本文を作成する
・FAQを含める
・まとめを含める
・本文を省略しない
・プレースホルダーを使わない
"""
return call_gemma4(system_prompt, user_prompt)
llm_client.py
import ollama
MODEL_NAME = "gemma4:e4b"
# Windows側OllamaのIPv4アドレスに置き換えてください。
# 例:OLLAMA_HOST = "http://192.168.x.x:11434"
OLLAMA_HOST = "http://192.168.x.x:11434"
client = ollama.Client(host=OLLAMA_HOST)
def call_gemma4(system_prompt: str, user_prompt: str) -> str:
"""
Gemma 4をOllama経由で呼び出す共通関数。
Planner / Writer / Reviewer の全役割で使う。
"""
response = client.chat(
model=MODEL_NAME,
messages=[
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": user_prompt,
},
],
)
return response["message"]["content"]main.py
from datetime import datetime
import re
from agents.planner import run_planner
from agents.writer import run_writer
from agents.reviewer import run_reviewer
from mcp_client import save_text_file
from validators import validate_html_fragment, sanitize_html_fragment
MAX_REVIEW_LOOPS = 3
def get_review_status(review: str) -> str:
"""
Reviewer AIの出力から判定を取り出す。
対応する形式:
- 判定:OK
- 判定: OK
- 判定:
OK
- 判定:
OK
戻り値:
- "OK"
- "修正必要"
- "UNKNOWN"
"""
lines = [line.strip() for line in review.splitlines() if line.strip()]
for i in range(len(lines) - 1, -1, -1):
line = lines[i].replace(":", ":").strip()
if not line.startswith("判定:"):
continue
value = line.replace("判定:", "", 1).strip()
# 「判定:」だけで、その次の行に OK / 修正必要 が出る場合
if value == "" and i + 1 < len(lines):
value = lines[i + 1].strip()
if value == "OK":
return "OK"
if value == "修正必要":
return "修正必要"
return "UNKNOWN"
return "UNKNOWN"
def is_review_ok(review: str) -> bool:
"""
Reviewer AIの判定がOKかどうかを確認する。
"""
return get_review_status(review) == "OK"
def slugify_keyword(keyword: str) -> str:
"""
フォルダ名に使いやすいようにキーワードを簡易変換する。
日本語はそのまま残し、使いにくい記号だけ置き換える。
"""
slug = keyword.strip()
slug = re.sub(r"\s+", "_", slug)
slug = re.sub(r'[\\/:*?"<>|]', "_", slug)
if not slug:
slug = "article"
return slug[:40]
def build_validation_text(issues: list[str]) -> str:
"""
Python側チェック結果を保存用テキストに変換する。
"""
if not issues:
return "Python側HTMLチェック:OK\n"
lines = [
"Python側HTMLチェック:修正必要",
"",
]
for issue in issues:
lines.append(f"- {issue}")
return "\n".join(lines)
def build_validation_review(issues: list[str]) -> str:
"""
Python側チェックで見つかった問題を、
Writer AIに渡せるレビュー文に変換する。
"""
issue_text = "\n".join(f"- {issue}" for issue in issues)
return f"""
Python側のHTML形式チェックで、以下の問題が見つかりました。
{issue_text}
Writer AIへの修正指示:
・上記の問題をすべて修正してください。
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
判定:修正必要
"""
def build_unknown_review_status_text(review: str) -> str:
"""
Reviewer AIの判定形式が不明な場合に、
Writer AIへ渡すための修正指示を作成する。
"""
return f"""
Reviewer AIの判定形式が不明でした。
Reviewer AIの出力:
{review}
問題:
・最後の判定行が「判定:OK」または「判定:修正必要」の形式になっていません。
・そのため、プログラム側でOK判定として扱えません。
Writer AIへの修正指示:
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
判定:修正必要
"""
def main():
print("Gemma 4ローカル・マルチエージェント記事作成システム")
print("-" * 50)
keyword = input("記事キーワードを入力してください: ").strip()
if not keyword:
print("キーワードが入力されていません。終了します。")
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
keyword_slug = slugify_keyword(keyword)
run_dir = f"output/{timestamp}_{keyword_slug}"
print(f"\n実行結果フォルダ: {run_dir}")
print("\n[1] Planner AI が記事設計を作成中...")
plan = run_planner(keyword)
save_text_file(f"{run_dir}/plan.txt", plan)
print("\n[2] Writer AI が初稿を作成中...")
article = run_writer(keyword=keyword, plan=plan)
# Writer出力をまずPython側で軽く整形する
article = sanitize_html_fragment(article)
save_text_file(f"{run_dir}/draft_1.html", article)
latest_review = ""
review_passed = False
final_review_status = "UNKNOWN"
final_validation_issues: list[str] = []
for loop_count in range(1, MAX_REVIEW_LOOPS + 1):
print(f"\n[3] Reviewer AI がレビュー中... ({loop_count}/{MAX_REVIEW_LOOPS})")
latest_review = run_reviewer(keyword=keyword, draft=article)
save_text_file(f"{run_dir}/review_{loop_count}.txt", latest_review)
print("\n--- Reviewer AI のレビュー結果 ---")
print(latest_review)
print("--- レビュー結果ここまで ---")
review_status = get_review_status(latest_review)
final_review_status = review_status
if review_status == "UNKNOWN":
print("\nReviewer AI の判定形式が不明です。修正必要として扱います。")
# ここでもう一度、保存前・検証前に自動整形する
article = sanitize_html_fragment(article)
validation_issues = validate_html_fragment(article)
final_validation_issues = validation_issues
validation_text = build_validation_text(validation_issues)
save_text_file(f"{run_dir}/validation_{loop_count}.txt", validation_text)
if validation_issues:
print("\nPython側HTMLチェック:修正必要")
for issue in validation_issues:
print(f"- {issue}")
if review_status == "OK" and not validation_issues:
print("\nReviewer AI + Python側HTMLチェック の判定:OK")
review_passed = True
break
print("\n判定:修正必要")
# 最大回数に達した場合は、これ以上Writerに修正させない。
# 未検証のdraft_4を作ってfinalにしてしまうのを防ぐ。
if loop_count == MAX_REVIEW_LOOPS:
print("\n最大レビュー回数に達しました。これ以上修正せず、最後に検証済みの記事を保存します。")
break
if validation_issues:
review_for_writer = build_validation_review(validation_issues)
elif review_status == "UNKNOWN":
review_for_writer = build_unknown_review_status_text(latest_review)
else:
review_for_writer = latest_review
print(f"\n[4] Writer AI がレビュー指摘に従って修正中... ({loop_count}/{MAX_REVIEW_LOOPS})")
article = run_writer(
keyword=keyword,
plan=plan,
review=review_for_writer,
previous_draft=article,
)
article = sanitize_html_fragment(article)
next_draft_number = loop_count + 1
save_text_file(f"{run_dir}/draft_{next_draft_number}.html", article)
print("\n[5] 最終HTMLを保存中...")
article = sanitize_html_fragment(article)
result = save_text_file(f"{run_dir}/final_article.html", article)
status_text = "OK判定後に保存" if review_passed else "最大レビュー回数到達後に保存"
if final_validation_issues:
validation_summary = "\n".join(f"- {issue}" for issue in final_validation_issues)
else:
validation_summary = "Python側HTMLチェック:OK"
summary = f"""実行キーワード:{keyword}
保存状態:{status_text}
Reviewer最終判定:{final_review_status}
最終保存先:{result['path']}
レビュー最大回数:{MAX_REVIEW_LOOPS}
実行結果フォルダ:{run_dir}
最終Python側HTMLチェック:
{validation_summary}
"""
save_text_file(f"{run_dir}/run_summary.txt", summary)
print("\n完了しました。")
print(f"保存先: {result['path']}")
if review_passed:
print("保存状態:Reviewer AI とPython側HTMLチェックのOK判定後に保存しました。")
else:
print("保存状態:最大レビュー回数に達したため、最後の記事を保存しました。")
print(f"Reviewer最終判定:{final_review_status}")
if __name__ == "__main__":
main()mcp_client.py
from mcp_server import save_article as tool_save_article
from mcp_server import save_text_file as tool_save_text_file
def save_article(filename: str, content: str) -> dict:
"""
記事保存用。
第3回では互換性維持のために残しておく。
"""
return tool_save_article(filename, content)
def save_text_file(filepath: str, content: str) -> dict:
"""
任意のテキストファイル保存用。
Planner / Writer / Reviewer / Validation の途中結果保存に使う。
"""
return tool_save_text_file(filepath, content)
mcp_server.py
from pathlib import Path
def save_text_file(filepath: str, content: str) -> dict:
"""
指定されたパスにテキストファイルを保存するMCP風ツール。
第3回時点では正式なMCPサーバーではなく、
将来MCP化しやすい関数として実装する。
"""
path = Path(filepath)
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(content, encoding="utf-8")
return {
"status": "ok",
"path": str(path),
}
def save_article(filename: str, content: str) -> dict:
"""
互換性維持用。
outputフォルダ直下に記事を保存する。
"""
output_dir = Path("output")
output_dir.mkdir(exist_ok=True)
path = output_dir / filename
path.write_text(content, encoding="utf-8")
return {
"status": "ok",
"path": str(path),
}
validators.py
import re
def convert_markdown_bold_to_strong(text: str) -> str:
"""
Markdownの **強調** を <strong>強調</strong> に変換する。
"""
return re.sub(
r"\*\*(.+?)\*\*",
r"<strong>\1</strong>",
text,
flags=re.DOTALL,
)
def strip_code_fences(text: str) -> str:
"""
LLMが誤って出力するコードブロック記号を取り除く。
"""
text = text.replace("```html", "")
text = text.replace("```HTML", "")
text = text.replace("```", "")
return text.strip()
def remove_style_and_script_blocks(text: str) -> str:
"""
<style>...</style> と <script>...</script> を削除する。
"""
text = re.sub(
r"<\s*style\b[^>]*>.*?<\s*/\s*style\s*>",
"",
text,
flags=re.IGNORECASE | re.DOTALL,
)
text = re.sub(
r"<\s*script\b[^>]*>.*?<\s*/\s*script\s*>",
"",
text,
flags=re.IGNORECASE | re.DOTALL,
)
return text
def remove_inline_style_attributes(text: str) -> str:
"""
style="..." または style='...' を削除する。
"""
text = re.sub(
r"\sstyle\s*=\s*\"[^\"]*\"",
"",
text,
flags=re.IGNORECASE,
)
text = re.sub(
r"\sstyle\s*=\s*'[^']*'",
"",
text,
flags=re.IGNORECASE,
)
return text
def extract_body_content_if_needed(text: str) -> str:
"""
LLMが <!DOCTYPE html> / html / head / body 付きで出力した場合、
body内の内容だけを取り出す。
bodyタグがない場合は、html/head/body系タグを削除する。
"""
body_match = re.search(
r"<\s*body\b[^>]*>(.*?)<\s*/\s*body\s*>",
text,
flags=re.IGNORECASE | re.DOTALL,
)
if body_match:
return body_match.group(1).strip()
# bodyタグがない場合は、HTML文書用タグだけ除去する
text = re.sub(r"<!DOCTYPE[^>]*>", "", text, flags=re.IGNORECASE)
text = re.sub(r"<\s*/?\s*html\b[^>]*>", "", text, flags=re.IGNORECASE)
text = re.sub(r"<\s*head\b[^>]*>.*?<\s*/\s*head\s*>", "", text, flags=re.IGNORECASE | re.DOTALL)
text = re.sub(r"<\s*/?\s*body\b[^>]*>", "", text, flags=re.IGNORECASE)
return text.strip()
def sanitize_html_fragment(article: str) -> str:
"""
Writer AIの出力を保存前に軽く自動整形する。
目的:
・Markdownの ** を <strong> に変換
・コードブロック記号を削除
・style/scriptタグを削除
・インラインstyle属性を削除
・html/head/body付きの場合は本文断片に近づける
"""
cleaned = article
cleaned = strip_code_fences(cleaned)
cleaned = extract_body_content_if_needed(cleaned)
cleaned = remove_style_and_script_blocks(cleaned)
cleaned = remove_inline_style_attributes(cleaned)
cleaned = convert_markdown_bold_to_strong(cleaned)
return cleaned.strip()
def validate_html_fragment(article: str) -> list[str]:
"""
Writer AIの出力をPython側で機械的にチェックする。
問題がなければ空のリストを返す。
"""
issues = []
forbidden_patterns = {
"styleタグが含まれています。<style>...</style> は出力しないでください。": r"<\s*style\b",
"インラインCSSが含まれています。style属性は使わないでください。": r"\sstyle\s*=",
"scriptタグが含まれています。JavaScriptは出力しないでください。": r"<\s*script\b",
"Markdownのコードブロック記号が含まれています。": r"```",
"Markdownの太字記法 ** が含まれています。HTMLのstrongタグに変換してください。": r"\*\*",
"htmlタグが含まれています。HTML断片として出力してください。": r"<\s*html\b",
"headタグが含まれています。HTML断片として出力してください。": r"<\s*head\b",
"bodyタグが含まれています。HTML断片として出力してください。": r"<\s*body\b",
}
for message, pattern in forbidden_patterns.items():
if re.search(pattern, article, flags=re.IGNORECASE):
issues.append(message)
placeholder_phrases = [
"(コンテンツ本文ここに挿入)",
"ここに本文を挿入",
"ここに挿入",
"以下略",
"省略",
]
for phrase in placeholder_phrases:
if phrase in article:
issues.append(
"本文がプレースホルダーまたは省略表現になっています。記事全文を出力してください。"
)
break
if "<h2" not in article:
issues.append("h2タグが見つかりません。記事本文にh2見出しを含めてください。")
if "<p" not in article:
issues.append("pタグが見つかりません。本文はpタグで記述してください。")
return issuesまとめ:途中保存でAI記事作成の失敗原因を可視化する
第3回では、AI記事作成の各段階を可視化し、問題の特定を容易にする仕組みを構築しました。
具体的には、以下の6つの段階をそれぞれファイルとして保存することで、どの工程で問題が発生したのかを追跡できるようにしました。
- Planner AIの設計
- Writer AIの初稿
- Reviewer AIのレビュー
- Python側HTMLチェック
- Writer AIの修正版
- 最終記事
この可視化により、第2回で採用したWriter AIとReviewer AIのループ処理では、出力品質が安定しないという課題が明確になりました。
対策として、第3回ではReviewer AIの判定結果をPython側で解析し、「OK」「修正必要」「UNKNOWN」の3つの状態として処理する方式に変更しました。
ただし、今後イベント駆動型マルチエージェントシステムへ発展させる際、自然言語のレビュー結果だけに依存して次の処理を決定するのは不安定です。
そのため、将来的な改善案として、Reviewer AIには自然言語レビューとは別にJSON形式の判定結果を出力させる予定です。
Python側でこのJSONを検証し、statusに応じて article.approved や article.revision_required といったイベントを発火させることで、より確実なシステムを作成する予定です。
次回の第4回では、MCP風ツールを整理し、より正式なMCP構成へ近づけていきます。