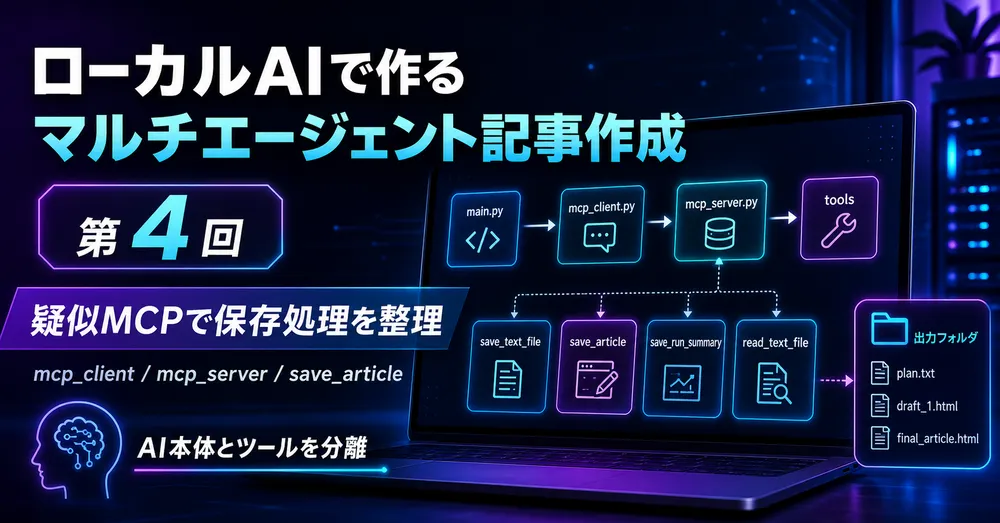
ローカルAIで作るマルチエージェント記事作成システム第4回。
第4回では、これまで mcp_client.py / mcp_server.py として作ってきたMCP風ツールを整理します。
加えて、第3回で増えた plan.txt、draft_1.html、review_1.txt、validation_1.txt、run_summary.txt などの保存処理も、AIエージェント本体から切り離して管理しやすくします。
この回では、MCPを使って「AIが外部ツールを呼び出す」とはどういうことかを、ローカルファイル保存ツールを例に理解していきます。
第3回AI記事作成までで何ができるようになったか
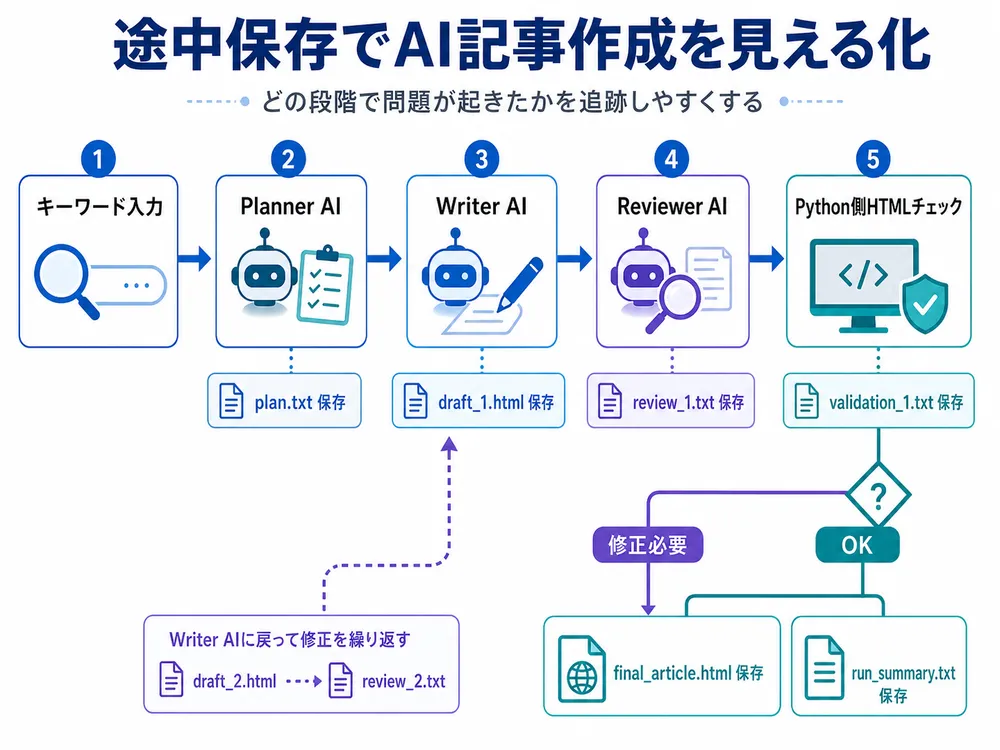
第3回では、Planner AI、Writer AI、Reviewer AIの途中結果を保存し、AI記事作成の失敗原因を追跡できるようにしました。
たとえば、1回の実行ごとに次のようなファイルを保存します。
plan.txt
draft_1.html
review_1.txt
validation_1.txt
draft_2.html
review_2.txt
validation_2.txt
final_article.html
run_summary.txt実際の実行結果でも、最終的に「OK判定後に保存」「Reviewer最終判定:OK」「Python側HTMLチェック:OK」となり、レビューと検証を通過した記事を保存できるようになりました。
ここで重要になるのが、保存処理をどこに置くかです。
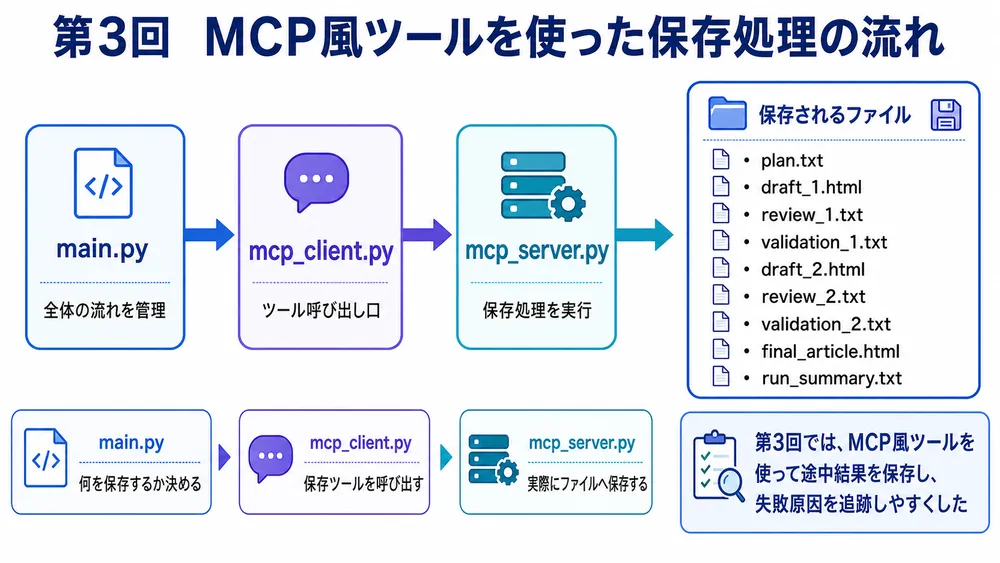
第3回AI記事作成までは、保存処理を mcp_server.py と mcp_client.py に分けていました。
main.py
↓
mcp_client.py
↓
mcp_server.py
↓
outputフォルダへ保存この構成は、まだ正式なMCP通信ではありません。
しかし、考え方としてはMCPに近い構成です。
つまり、AIエージェント本体である main.py が、直接ファイル保存の細かい処理を持つのではなく、保存ツールを呼び出しているという形です。
第4回AI記事作成では、このMCP風ツールを整理して、今後正式なMCP構成へ発展させやすくします。
MCPとは何かを簡単に整理する
MCPは、AIと外部ツールをつなぐための仕組みです。
ここでいう外部ツールとは、たとえば次のようなものです。
・ファイルを保存する
・ファイルを読み込む
・Web検索する
・データベースを検索する
・メールやカレンダーと連携する
・ログを保存するAIは文章を考えたり、判断したりすることは得意です。
しかし、実際にファイルを書き込む、外部サービスへ接続する、検索結果を取得する、といった作業はツールに任せる方が安全です。
イメージとしては、次のようになります。
AIエージェント
↓
MCP Client
↓
MCP Server
↓
外部ツール今回のシステムでは、まだ正式なMCP Serverを立てているわけではありません。
ただし、構造としては次のように分けています。
main.py
↓
mcp_client.py
↓
mcp_server.py
↓
ファイル保存ツールこのため、今回の段階では「MCP風ツール」と呼んでいます。
第3回AI記事作成でMCP風ツールを整理する理由
第1回AI記事作成の最小実装では、記事を1つ保存するだけでした。
しかし、第3回まで進むと、保存するファイルが増えました。
Planner AIの出力
Writer AIの初稿
Reviewer AIのレビュー
Python側HTMLチェック結果
Writer AIの修正版
最終記事
実行サマリーこれらをすべて main.py の中で直接保存すると、コードが読みにくくなります。
たとえば、main.py の役割は本来、次のような全体の流れを管理することです。
・キーワードを受け取る
・Planner AIを呼ぶ
・Writer AIを呼ぶ
・Reviewer AIを呼ぶ
・Python側チェックを行う
・OKなら保存する一方で、ファイル保存の具体的な処理は、別の場所に切り出した方がよいです。
・フォルダを作る
・ファイル名を決める
・UTF-8で保存する
・保存結果を返すこのように、役割を分けることでコードが整理されます。
main.py
→ AIエージェント全体の流れを管理する
mcp_client.py
→ ツールを呼び出す入口
mcp_server.py
→ 実際の保存処理を実行する現在のMCP風構成
現在の構成は、次のようになっています。
article-agent/
├ main.py
├ llm_client.py
├ validators.py
├ agents/
│ ├ planner.py
│ ├ writer.py
│ └ reviewer.py
├ mcp_client.py
├ mcp_server.py
└ output/それぞれの役割は以下です。
| ファイル | 役割 |
|---|---|
main.py | 全体の処理フローを管理する |
planner.py | 記事設計を作成する |
writer.py | 記事本文を作成・修正する |
reviewer.py | 記事をレビューする |
validators.py | HTMLやMarkdown混入をチェック・整形する |
mcp_client.py | ツール呼び出しの入口 |
mcp_server.py | 保存処理などのツール本体 |
output/ | 実行結果を保存するフォルダ |
この中で、第4回AI記事作成で変更を行うファイルは次の2つになります。
mcp_client.py
mcp_server.pymcp_server.py の役割
mcp_server.py は、実際にツール処理を行う場所です。
第3回では、主にファイル保存を行っていました。
たとえば、指定されたパスにテキストを保存する関数です。
mcp_server.py
from pathlib import Path
def save_text_file(filepath: str, content: str) -> dict:
"""
指定されたパスにテキストファイルを保存するMCP風ツール。
"""
path = Path(filepath)
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(content, encoding="utf-8")
return {
"status": "ok",
"path": str(path),
}この関数は、次の処理をまとめています。
・保存先パスを受け取る
・親フォルダがなければ作る
・ファイルをUTF-8で保存する
・保存結果をdictで返すここで重要なのは、main.py がファイル保存の細かい処理を知らなくてよいことです。
main.py は、次のように呼び出すだけです。
save_text_file(f"{run_dir}/plan.txt", plan)これにより、保存方法を変更したくなった場合も、基本的には mcp_server.py のみを修正すれば済みます。
mcp_client.py の役割
mcp_client.py は、ツールを呼び出すための入口です。
現在は、mcp_server.py の関数をそのまま呼び出しています。
from mcp_server import save_text_file as tool_save_text_file
def save_text_file(filepath: str, content: str) -> dict:
"""
任意のテキストファイル保存用。
Planner / Writer / Reviewer / Validation の途中結果保存に使う。
"""
return tool_save_text_file(filepath, content)この段階では、ただの関数呼び出しに見えます。
しかし、ここに mcp_client.py を挟むことで、将来的に正式なMCP通信へ置き換えやすくなります。
現在:
mcp_client.py
↓
Python関数として mcp_server.py を呼ぶ将来:
MCP Client
↓
MCP Serverへ通信してツールを呼ぶつまり、mcp_client.py は、今後の拡張に備えた「接続口」のような位置づけです。
第4回AI記事作成で整理するツール
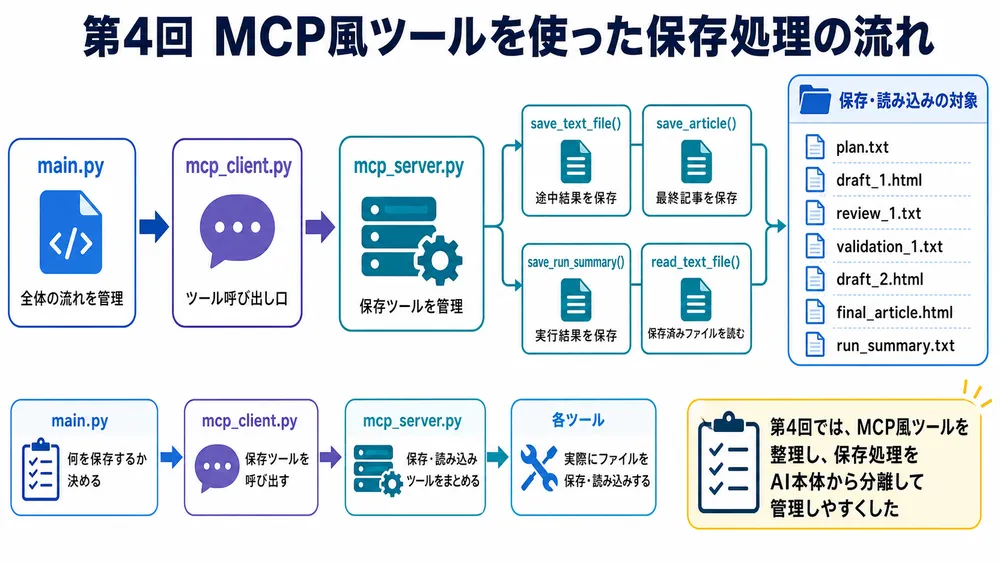
第4回では、保存処理を以下のように整理します。
save_text_file()
save_article()
save_run_summary()
read_text_file()それぞれの役割は以下です。
| ツール名 | 役割 |
|---|---|
save_text_file() | 任意のテキストファイルを保存する |
save_article() | 最終記事を保存する |
save_run_summary() | 実行結果の概要を保存する |
read_text_file() | 保存済みファイルを読み込む |
第3回AI記事作成では保存が中心でしたが、第4回では読み込みも追加します。
なぜなら、今後は次のような処理が必要になる可能性があるからです。
・前回のレビュー結果を読み込む
・保存済みのdraftを再確認する
・過去のrun_summaryを確認する
・途中保存ファイルを別のAIに渡すつまり、保存だけでなく、保存したものを再利用する 構成に近づけます。
第4回AI記事作成での改善後イメージ
第4回の改善後は、次のような構成になります。
main.py
↓
mcp_client.py
↓
mcp_server.py
├ save_text_file()
├ save_article()
├ save_run_summary()
└ read_text_file()ここで大事なのは、main.py が「どう保存するか」ではなく、「何を保存するか」に集中できることです。
main.pyが考えること:
・planを保存する
・draftを保存する
・reviewを保存する
・validationを保存する
・final_articleを保存する
mcp_server.pyが担当すること:
・フォルダを作る
・ファイルを書き込む
・ファイルを読み込む
・結果を返すこの分離が、AIエージェントを拡張しやすくします。
正式なMCPとの違い
ここで注意したいのは、第4回の時点ではまだ正式なMCPではないという点です。
現在は、Pythonファイル内で関数を呼んでいます。
現在:
main.py → mcp_client.py → mcp_server.py の関数呼び出し正式なMCP構成では、MCP Serverが独立したサーバーとして動き、Clientが通信してツールを呼びます。
正式MCP:
AIアプリ
↓
MCP Client
↓
MCP Server
↓
Toolただし、考え方は同じです。
AI本体とツール処理を分ける第4回では、この考え方をローカル関数で処理している段階です。
正式なMCP構成
正式なMCPサーバーを使う流れは、AI記事作成プログラムが直接ファイル保存するのではなく、MCP Clientを通じてMCP Serverへ依頼し、MCP Serverが保存ツールを実行する仕組みです。
以下の図は、正式なMCPサーバーを使った場合、AI記事作成プログラムと保存処理がどのようにつながるかを表しています。
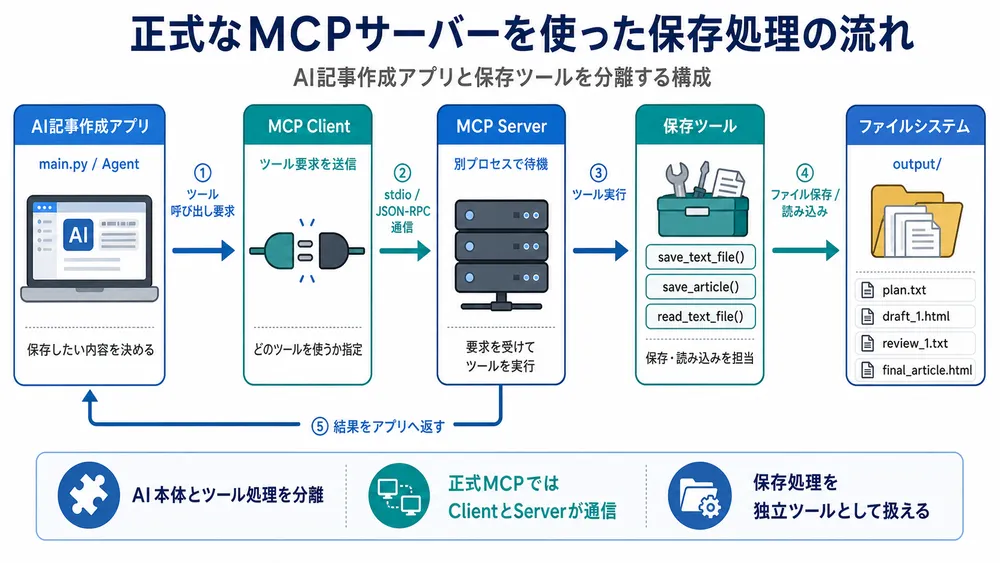
参考情報:正式なMCPサーバー使用例
実際にMCPサーバーを使った処理に関しては、AIエージェント入門|ローカルファイル操作AIを作る【第5週・上級編】の記事を参考にしてください。
第5回へのつながり
第4回でローカルツールを整理すると、次に進めるのは外部情報取得です。
現在のシステムにはWeb検索機能がありません。
そのため、キーワードに「最新」「2026年」「新機能」などを入れても、Gemma 4が実際にWebを検索して最新情報を取得しているわけではありません。
そこで第5回では、次のように発展させます。
Researcher AI
↓
Web検索MCP
↓
検索結果
↓
Writer AIつまり、第4回ではローカルファイル保存ツールを整理し、第5回ではWeb検索のような外部ツール連携へ進みます。
第4回AI記事作成 変更ファイル
第4回では、主に次の変更を行いました。
main.py
→ 何を保存するかを判断する
mcp_client.py
→ 保存・読み込みツールを呼び出す入口
mcp_server.py
→ 実際にファイル保存・読み込みを行う疑似MCPツール本体以下に、第4回で変更する 3つのファイル を記載します。
これ以外のファイルは、第3回AI記事作成で使用したファイルと同じです。
mcp_server.py
from pathlib import Path
def save_text_file(filepath: str, content: str) -> dict:
"""
指定されたパスにテキストファイルを保存する疑似MCPツール。
第4回では、保存処理の基本ツールとして使う。
plan.txt / draft_1.html / review_1.txt / validation_1.txt など、
任意の途中結果を保存できる。
"""
path = Path(filepath)
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(content, encoding="utf-8")
return {
"status": "ok",
"tool": "save_text_file",
"path": str(path),
}
def save_article(run_dir: str, content: str, filename: str = "final_article.html") -> dict:
"""
最終記事を保存する疑似MCPツール。
save_text_file() でも保存できるが、
最終記事であることを分かりやすくするために専用関数として分ける。
"""
filepath = Path(run_dir) / filename
result = save_text_file(str(filepath), content)
return {
"status": result["status"],
"tool": "save_article",
"path": result["path"],
}
def save_run_summary(run_dir: str, content: str, filename: str = "run_summary.txt") -> dict:
"""
実行結果の概要を保存する疑似MCPツール。
キーワード、保存状態、Reviewer判定、Python側チェック結果などを
run_summary.txt として保存する。
"""
filepath = Path(run_dir) / filename
result = save_text_file(str(filepath), content)
return {
"status": result["status"],
"tool": "save_run_summary",
"path": result["path"],
}
def read_text_file(filepath: str) -> dict:
"""
指定されたテキストファイルを読み込む疑似MCPツール。
第4回では、将来的に保存済みの draft / review / summary を
再利用できるようにするため、読み込み用ツールも追加する。
"""
path = Path(filepath)
if not path.exists():
return {
"status": "error",
"tool": "read_text_file",
"path": str(path),
"message": "file not found",
"content": "",
}
content = path.read_text(encoding="utf-8")
return {
"status": "ok",
"tool": "read_text_file",
"path": str(path),
"content": content,
}mcp_client.py
from mcp_server import save_text_file as tool_save_text_file
from mcp_server import save_article as tool_save_article
from mcp_server import save_run_summary as tool_save_run_summary
from mcp_server import read_text_file as tool_read_text_file
def save_text_file(filepath: str, content: str) -> dict:
"""
任意のテキストファイル保存用の呼び出し口。
Planner / Writer / Reviewer / Validation の途中結果保存に使う。
"""
return tool_save_text_file(filepath, content)
def save_article(run_dir: str, content: str, filename: str = "final_article.html") -> dict:
"""
最終記事保存用の呼び出し口。
main.py からは、最終記事を保存する意図が分かるように
save_article() として呼び出す。
"""
return tool_save_article(run_dir, content, filename)
def save_run_summary(run_dir: str, content: str, filename: str = "run_summary.txt") -> dict:
"""
実行結果サマリー保存用の呼び出し口。
"""
return tool_save_run_summary(run_dir, content, filename)
def read_text_file(filepath: str) -> dict:
"""
保存済みテキストファイル読み込み用の呼び出し口。
第4回時点では使用頻度は高くないが、
今後の正式MCP化やイベント駆動型への発展を見据えて追加する。
"""
return tool_read_text_file(filepath)main.py
from datetime import datetime
import re
from agents.planner import run_planner
from agents.writer import run_writer
from agents.reviewer import run_reviewer
from mcp_client import save_text_file, save_article, save_run_summary
from validators import validate_html_fragment, sanitize_html_fragment
MAX_REVIEW_LOOPS = 3
def get_review_status(review: str) -> str:
"""
Reviewer AIの出力から判定を取り出す。
対応する形式:
- 判定:OK
- 判定: OK
- 判定:
OK
- 判定:
OK
戻り値:
- "OK"
- "修正必要"
- "UNKNOWN"
"""
lines = [line.strip() for line in review.splitlines() if line.strip()]
for i in range(len(lines) - 1, -1, -1):
line = lines[i].replace(":", ":").strip()
if not line.startswith("判定:"):
continue
value = line.replace("判定:", "", 1).strip()
# 「判定:」だけで、その次の行に OK / 修正必要 が出る場合
if value == "" and i + 1 < len(lines):
value = lines[i + 1].strip()
if value == "OK":
return "OK"
if value == "修正必要":
return "修正必要"
return "UNKNOWN"
return "UNKNOWN"
def is_review_ok(review: str) -> bool:
"""
Reviewer AIの判定がOKかどうかを確認する。
"""
return get_review_status(review) == "OK"
def slugify_keyword(keyword: str) -> str:
"""
フォルダ名に使いやすいようにキーワードを簡易変換する。
日本語はそのまま残し、使いにくい記号だけ置き換える。
"""
slug = keyword.strip()
slug = re.sub(r"\s+", "_", slug)
slug = re.sub(r'[\\/:*?"<>|]', "_", slug)
if not slug:
slug = "article"
return slug[:40]
def build_validation_text(issues: list[str]) -> str:
"""
Python側チェック結果を保存用テキストに変換する。
"""
if not issues:
return "Python側HTMLチェック:OK\n"
lines = [
"Python側HTMLチェック:修正必要",
"",
]
for issue in issues:
lines.append(f"- {issue}")
return "\n".join(lines)
def build_validation_review(issues: list[str]) -> str:
"""
Python側チェックで見つかった問題を、
Writer AIに渡せるレビュー文に変換する。
"""
issue_text = "\n".join(f"- {issue}" for issue in issues)
return f"""
Python側のHTML形式チェックで、以下の問題が見つかりました。
{issue_text}
Writer AIへの修正指示:
・上記の問題をすべて修正してください。
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
判定:修正必要
"""
def build_unknown_review_status_text(review: str) -> str:
"""
Reviewer AIの判定形式が不明な場合に、
Writer AIへ渡すための修正指示を作成する。
"""
return f"""
Reviewer AIの判定形式が不明でした。
Reviewer AIの出力:
{review}
問題:
・最後の判定行が「判定:OK」または「判定:修正必要」の形式になっていません。
・そのため、プログラム側でOK判定として扱えません。
Writer AIへの修正指示:
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
判定:修正必要
"""
def main():
print("Gemma 4ローカル・マルチエージェント記事作成システム")
print("-" * 50)
keyword = input("記事キーワードを入力してください: ").strip()
if not keyword:
print("キーワードが入力されていません。終了します。")
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
keyword_slug = slugify_keyword(keyword)
run_dir = f"output/{timestamp}_{keyword_slug}"
print(f"\n実行結果フォルダ: {run_dir}")
print("\n[1] Planner AI が記事設計を作成中...")
plan = run_planner(keyword)
# 第4回:途中結果は save_text_file() で保存
save_text_file(f"{run_dir}/plan.txt", plan)
print("\n[2] Writer AI が初稿を作成中...")
article = run_writer(keyword=keyword, plan=plan)
# Writer出力をPython側で軽く整形する
article = sanitize_html_fragment(article)
save_text_file(f"{run_dir}/draft_1.html", article)
latest_review = ""
review_passed = False
final_review_status = "UNKNOWN"
final_validation_issues: list[str] = []
for loop_count in range(1, MAX_REVIEW_LOOPS + 1):
print(f"\n[3] Reviewer AI がレビュー中... ({loop_count}/{MAX_REVIEW_LOOPS})")
latest_review = run_reviewer(keyword=keyword, draft=article)
save_text_file(f"{run_dir}/review_{loop_count}.txt", latest_review)
print("\n--- Reviewer AI のレビュー結果 ---")
print(latest_review)
print("--- レビュー結果ここまで ---")
review_status = get_review_status(latest_review)
final_review_status = review_status
if review_status == "UNKNOWN":
print("\nReviewer AI の判定形式が不明です。修正必要として扱います。")
# 保存前・検証前に自動整形する
article = sanitize_html_fragment(article)
validation_issues = validate_html_fragment(article)
final_validation_issues = validation_issues
validation_text = build_validation_text(validation_issues)
save_text_file(f"{run_dir}/validation_{loop_count}.txt", validation_text)
if validation_issues:
print("\nPython側HTMLチェック:修正必要")
for issue in validation_issues:
print(f"- {issue}")
if review_status == "OK" and not validation_issues:
print("\nReviewer AI + Python側HTMLチェック の判定:OK")
review_passed = True
break
print("\n判定:修正必要")
# 最大回数に達した場合は、これ以上Writerに修正させない。
# 未検証のdraft_4を作ってfinalにしてしまうのを防ぐ。
if loop_count == MAX_REVIEW_LOOPS:
print("\n最大レビュー回数に達しました。これ以上修正せず、最後に検証済みの記事を保存します。")
break
if validation_issues:
review_for_writer = build_validation_review(validation_issues)
elif review_status == "UNKNOWN":
review_for_writer = build_unknown_review_status_text(latest_review)
else:
review_for_writer = latest_review
print(f"\n[4] Writer AI がレビュー指摘に従って修正中... ({loop_count}/{MAX_REVIEW_LOOPS})")
article = run_writer(
keyword=keyword,
plan=plan,
review=review_for_writer,
previous_draft=article,
)
article = sanitize_html_fragment(article)
next_draft_number = loop_count + 1
save_text_file(f"{run_dir}/draft_{next_draft_number}.html", article)
print("\n[5] 最終HTMLを保存中...")
article = sanitize_html_fragment(article)
# 第4回:最終記事は save_article() で保存
result = save_article(run_dir, article)
status_text = "OK判定後に保存" if review_passed else "最大レビュー回数到達後に保存"
if final_validation_issues:
validation_summary = "\n".join(f"- {issue}" for issue in final_validation_issues)
else:
validation_summary = "Python側HTMLチェック:OK"
summary = f"""実行キーワード:{keyword}
保存状態:{status_text}
Reviewer最終判定:{final_review_status}
最終保存先:{result['path']}
レビュー最大回数:{MAX_REVIEW_LOOPS}
実行結果フォルダ:{run_dir}
最終Python側HTMLチェック:
{validation_summary}
"""
# 第4回:実行結果は save_run_summary() で保存
save_run_summary(run_dir, summary)
print("\n完了しました。")
print(f"保存先: {result['path']}")
if review_passed:
print("保存状態:Reviewer AI とPython側HTMLチェックのOK判定後に保存しました。")
else:
print("保存状態:最大レビュー回数に達したため、最後の記事を保存しました。")
print(f"Reviewer最終判定:{final_review_status}")
if __name__ == "__main__":
main()第4回AI記事作成 実行結果
第4回作業ターミナル出力
UTF-8
SHIFT JIS
第4回作成記事
UTF-8
SHIFT-JIS
まとめ:MCP風ツールはAIエージェントを拡張する入口
第4回では、第3回までで使ってきた mcp_client.py と mcp_server.py を整理し、MCP風ツールとしての役割を確認しました。
重要なのは、次の考え方です。
AIエージェント本体
↓
ツール呼び出し口
↓
ツール本体
↓
外部処理今回の例では、外部処理はローカルファイル保存でした。
しかし、同じ考え方を使えば、将来的に次のようなツールへ発展できます。
・ファイル読み込み
・Web検索
・データベース検索
・メール送信
・カレンダー連携
・外部API呼び出し第4回では、保存処理を疑似MCPツールとして整理し、AI記事作成の本体とファイル保存・読み込み処理を分離しました。
これにより、保存処理は整理できましたが、マルチエージェント構成をさらに安定させるには、もう一つ重要な課題があります。
AIエージェント間の受け渡しをJSON化
それが、エージェント間で受け渡す「判定結果の形式」です。
第3回では、Reviewer AIの自然文レビューから「判定:OK」や「判定:修正必要」をPython側で読み取っていました。
しかし、LLMの出力は揺れるため、自然文だけに頼ると判定ミスが起きる可能性があります。
そこで第5回では、Reviewer AIのレビュー結果をJSON形式で受け渡し、Python側でstatusを検証して次の処理を決める構成に進みます。
これにより、将来的なイベント駆動型マルチエージェントへ発展しやすい、安定したエージェント間インターフェースを作っていきます。

