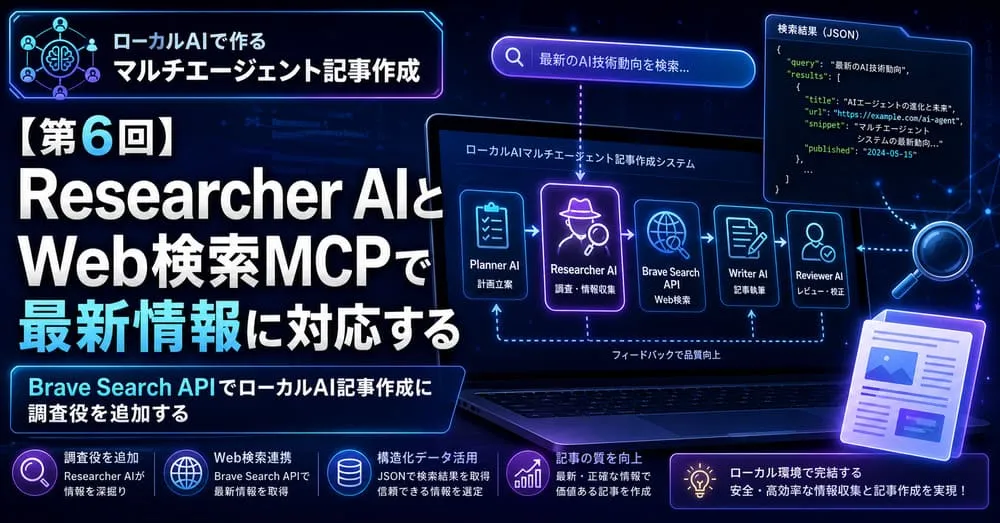
第6回AI記事作成では、Planner AI、Writer AI、Reviewer AIに加えて、調査役となるResearcher AIを追加します。
ローカルLLMは便利ですが、単体では最新ニュースや現在の製品情報、直近のアップデート内容を自動取得できません。
そこでBrave Search APIを使ったWeb検索MCP風ツールを追加し、Researcher AIが検索結果を整理してWriter AIへ渡すことで、最新情報を踏まえた記事作成へ発展させます。
- 第5回AI記事作成まででできたこと
- なぜResearcher AIが必要なのか
- Researcher AIの役割
- 第6回AI記事作成ではBrave Search APIを使う
- Brave Search APIを使うために必要なもの
- 第6回AI記事作成で追加する全体像
- Web検索MCP風ツールとは何か
- 第6回AI記事作成でのファイル構成
- Researcher AIが作る調査メモ
- Writer AIへの渡し方
- Web検索結果をそのまま信じない
- 第6回AI記事作成の処理途中で保存するファイル
- 第6回AI記事作成でできること
- 第6回AI記事作成の実行と実行結果
- まとめ:Brave Search APIでローカルLLMの弱点を補う
第5回AI記事作成まででできたこと
第5回では、Reviewer AIの判定結果をJSON形式で受け渡す構成にしました。
それまでは、Reviewer AIの自然文レビューから、
判定:OK
判定:修正必要のような行をPython側で読み取り、次の処理を判断していました。
しかし、LLMの出力は揺れます。
判定:OK
判定:
OK
判定:このまま公開可能
判定:A+このような出力は、人間には意味が分かっても、Python側では安定して処理しにくい問題があります。
そこで第5回では、Reviewer AIの結果を次のようなJSONとして受け渡す構成にしました。
{
"status": "OK",
"summary": "記事構成とHTML形式に大きな問題はありません。",
"issues": [],
"next_action": "SAVE"
}これにより、AIエージェント間の受け渡しが安定し、将来的なイベント駆動型にも発展させやすくなりました。
そして第6回AI記事作成では、次の課題の最新情報への対応を実装します。
なぜResearcher AIが必要なのか
これまでのシステムでは、Planner AI、Writer AI、Reviewer AIが記事作成を担当していました。
Planner AI
↓
Writer AI
↓
Reviewer AI
↓
Python側チェック
↓
保存この構成でも、一般的な解説記事は作成できます。
たとえば、以下のようなテーマであれば、ローカルLLMだけでもある程度対応できます。
・ブロックチェーンとは何か
・AIエージェントとは何か
・SEO記事の基本構成
・Pythonの仮想環境とは何か
・MCPの考え方しかし、次のようなテーマでは問題が出やすくなります。
・2026年時点の最新AIモデル
・最新のWordPressアップデート
・直近のGoogle検索アルゴリズム変更
・現在公開されているツールやライブラリ
・最新ニュースを反映した記事ローカルLLMは、基本的にモデルに学習済みの知識をもとに回答します。
そのため、現在のWeb情報を自動で見に行くわけではありません。
キーワードに「最新」「2026年」「新機能」「リリース」などを入れても、ローカルLLMが実際に検索しているわけではないため、古い情報や推測が混ざる可能性があります。
そこで必要になるのが、調査担当のAIエージェントです。
それが、今回追加する Researcher AI です。
Researcher AIの役割
Researcher AIは、記事を書くAIではありません。
役割は、記事を書く前に必要な情報を集め、整理することです。
具体的には、次のような作業を担当します。
・検索キーワードを作る
・Web検索MCP風ツールへ検索依頼を出す
・Brave Search APIの検索結果を受け取る
・重要な情報を整理する
・出典URLをまとめる
・Writer AIに渡す調査メモを作るつまり、Researcher AIは、記事作成における「調査担当」です。
人間の作業でたとえると、次のような役割です。
編集者:
記事の方向性を決める
リサーチ担当:
必要な資料や最新情報を集める
ライター:
集めた情報をもとに記事を書く
校閲担当:
内容を確認するAIエージェント構成に置き換えると、こうなります。
Planner AI
→ 記事設計
Researcher AI
→ 最新情報・参考情報の収集
Writer AI
→ 記事本文の作成
Reviewer AI
→ 内容・構成・HTML形式の確認第6回AI記事作成ではBrave Search APIを使う
第6回AI記事作成では、Web検索部分に Brave Search API を使います。
Brave Search APIは、Braveの検索インデックスを利用してWeb検索結果を取得できるAPIです。
公式ドキュメントでは、Web検索APIのエンドポイントとして https://api.search.brave.com/res/v1/web/search が案内され、X-Subscription-Token ヘッダーでAPIキーを渡す形式が示されています。
参考:
Documentation – Brave Search API
Search – API Reference
今回のシリーズでは、検索処理を以下のように整理します。
Researcher AI
↓
Web検索MCP風ツール
↓
Brave Search API
↓
JSON形式の検索結果
↓
Researcher AIが調査メモ化Brave Search APIを使う理由は、検索結果をJSON形式で扱えるからです。
検索結果がJSONで返ってくると、Python側で次のような情報を取り出しやすくなります。
・title
・url
・description
・検索クエリ
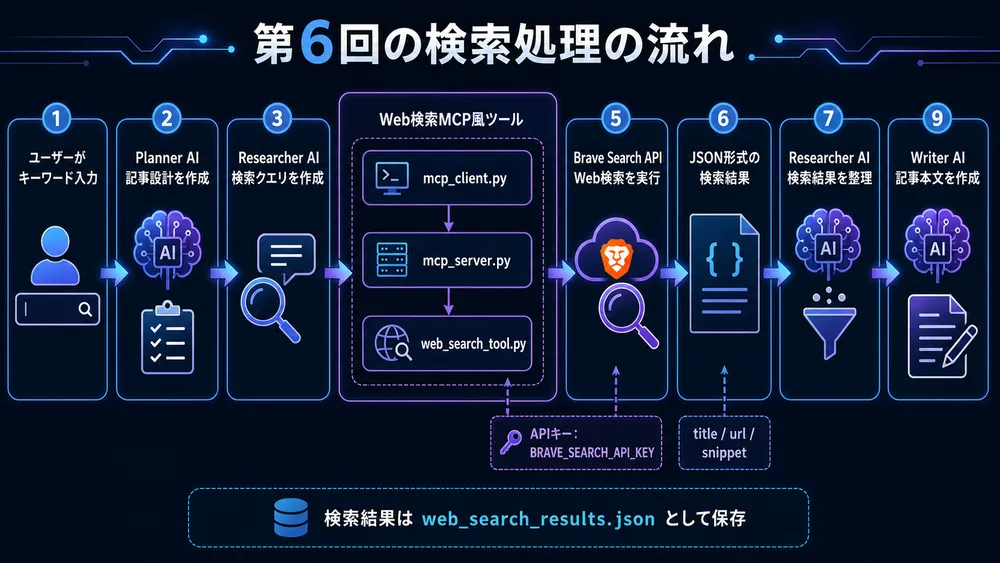
・検索結果の件数これにより、web_search_results.json として保存しやすくなり、Researcher AIへ渡す調査材料としても扱いやすくなります。
Brave Search APIを使うために必要なもの
Brave Search APIを使うには、APIキーが必要です。Brave公式の認証ガイドでは、すべてのリクエストに X-Subscription-Token ヘッダーでサブスクリプショントークンを含める必要があると説明されています。
APIキーは、Pythonコードに直接書かず、環境変数として管理します。
WSLやGit Bashで一時的に設定する場合は、以下のようにします。
export BRAVE_SEARCH_API_KEY="ここに取得したAPIキー"設定した環境変数の確認方法は以下の通りです。
echo $BRAVE_SEARCH_API_KEY永続的に使う場合は、今回のWSL環境では、以下のコマンドで、 ~/.bashrc に追記します。
echo 'export BRAVE_SEARCH_API_KEY="ここに取得したAPIキー"' >> ~/.bashrc
source ~/.bashrcAPIキーをPythonファイルに直接書くと、GitHubなどへ公開した際に漏えいする危険があります。必ず環境変数や .env で管理し、公開リポジトリには含めないようにします。
Brave Search APIの取得方法
Brave Search API アカウントの作成
まず、API専用のポータルサイトにアクセスします。
- Brave Search API Dashboard にアクセスします。
- 「Sign Up」 をクリックします。
- メールアドレス、または Google / GitHub アカウントを使用してサインアップします。
2. プランの選択と支払い設定
Brave Search APIは従量課金制ですが、初回登録時に5ドル分の無料クレジットが付与されることが一般的です。
- ダッシュボードの 「Settings」 または 「Billing」 タブに移動します。
- クレジットカード情報を登録します(無料枠内であっても、本人確認と悪用防止のために登録が必要です)。
- 利用目的に合わせてプラン(Search, Answers, LLM Contextなど)を選択します。
(今回は、基本の「Search」プランを選択します。)
3. APIキーの生成
インフラの準備が整ったら、実際に通信に使う「鍵」を発行します。
- ダッシュボードの 「API Keys」 セクションへ移動します。
- 「Create New Key」 をクリックします。
- キーに名前(例:
Dev-Desktop-WSL2など)を付けて保存します。 - 重要: キーは一度しか表示されません。必ず安全なパスワードマネージャー等に保存してください。
4. 接続テスト(クイックスタート)
APIキーが正しく動作するか、ターミナル(WSL2やコマンドプロンプト)から curl コマンドで確認します。
curl -s -X GET "https://api.search.brave.com/res/v1/web/search?q=brave+search+api" \
-H "Accept: application/json" \
-H "X-Subscription-Token: <取得したAPIキー>"正常にレスポンスが返ってくれば、取得完了です。
なお、Brave Search APIの料金は変更される可能性があります。
現在の公式料金ページでは、Search APIは $5.00 per 1,000 requests と表示され、毎月$5分のクレジットが含まれると案内されています。
利用前に最新の料金ページを確認してください。
第6回AI記事作成で追加する全体像
第6回AI記事作成では、これまでの流れにResearcher AIを追加します。
キーワード入力
↓
Planner AI
↓
Researcher AI
↓
Brave Search API
↓
Researcher AI
↓
Writer AI
↓
Reviewer AI
↓
Python側チェック
↓
保存もう少し詳しく見ると、以下のようになります。
1. ユーザーがキーワードを入力
2. Planner AIが記事構成を作る
3. Researcher AIがWeb検索キーワードを作る
4. Web検索MCP風ツールがBrave Search APIへ検索リクエストを送る
5. Brave Search APIからJSON形式の検索結果を受け取る
6. Researcher AIが検索結果を調査メモに整理する
7. Writer AIが記事設計と調査メモをもとに記事を書く
8. Reviewer AIが記事をレビューする
9. Python側でHTML形式を検証する
10. OKなら保存する第6回AI記事作成のポイントは、Writer AIにいきなり記事を書かせないことです。
先にResearcher AIが情報を整理し、その結果をWriter AIへ渡します。
Researcher AIが調査メモに整理し、Writer AIに渡す
Web検索MCP風ツールとは何か
ここでいうWeb検索MCP風ツールは、正式なMCPサーバーではありません。
第4回と同じように、Python関数で疑似的にMCPの考え方を再現したものです。
main.py
↓
mcp_client.py
↓
mcp_server.py
↓
web_search_tool.py
↓
Brave Search APIこの流れにすることで、main.py は「検索したい」という依頼を出すだけで済みます。
実際にAPIキーを使ってBrave Search APIへアクセスする処理は、web_search_tool.py にまとめます。
つまり、役割は以下のように分かれます。
main.py
→ 全体の流れを管理する
mcp_client.py
→ Web検索ツールを呼び出す入口
mcp_server.py
→ Web検索ツールを実行する疑似MCPサーバー
web_search_tool.py
→ Brave Search APIへアクセスして検索結果を取得する実際にWeb検索を行う場所
実際にWeb検索を行うのは、web_search_tool.py の web_search() 関数です。
Brave Search API版では、検索エンドポイントに対して、以下のようにリクエストを送ります。
BRAVE_SEARCH_ENDPOINT = "https://api.search.brave.com/res/v1/web/search"検索クエリはURLパラメータとして渡します。
params = urllib.parse.urlencode({
"q": query,
"count": max_results,
"country": "JP",
"search_lang": "ja",
"safesearch": "moderate",
})そして、APIキーはHTTPヘッダーで渡します。
headers={
"Accept": "application/json",
"Accept-Encoding": "gzip",
"X-Subscription-Token": api_key,
}Brave Search APIはREST形式で利用でき、リクエスト時にはAPIキーを X-Subscription-Token ヘッダーに含める必要があります。
Brave Search API版の web_search_tool.py の考え方
第6回AI記事作成では、web_search_tool.py を以下の考え方で作ります。
1. 環境変数 BRAVE_SEARCH_API_KEY を読む
2. 検索クエリを受け取る
3. Brave Search APIへリクエストする
4. JSONレスポンスを受け取る
5. title / url / snippet に整形する
6. main.pyへ検索結果を返す返す形式は、次のように統一しておきます。
{
"status": "ok",
"tool": "web_search",
"provider": "brave_search_api",
"query": "AIエージェント 2026年 最新動向",
"results": [
{
"title": "検索結果タイトル",
"url": "https://example.com",
"snippet": "検索結果の概要"
}
]
}第6回AI記事作成でのファイル構成
第6回AI記事作成のファイル構成は、以下の通りです。
article-agent/
├ main.py
├ llm_client.py
├ validators.py
├ review_parser.py
├ agents/
│ ├ planner.py
│ ├ researcher.py
│ ├ writer.py
│ └ reviewer.py
├ mcp_client.py
├ mcp_server.py
├ web_search_tool.py
└ output/新しく追加するファイルは、以下になります。
agents/researcher.py
web_search_tool.py変更するファイルは以下です。
main.py
agents/writer.py
mcp_client.py
mcp_server.py第6回AI記事作成では、Researcher AIを追加し、Writer AIへ調査メモを渡すため、main.py と agents/writer.py にも変更が入ります。
Researcher AIが作る調査メモ
Researcher AIが最終的にWriter AIへ渡すのは、検索結果そのものではなく、整理済みの調査メモです。
たとえば、キーワードが次のような場合を考えます。
AIエージェント 2026年 最新動向Researcher AIは、Brave Search APIの検索結果をもとに次のようなメモを作ります。
調査メモ:
1. 主要な論点
- AIエージェントは、単なるチャットボットではなく、計画・実行・検証を含むワークフローとして整理されることが多い。
- 2026年時点では、業務自動化、開発支援、検索・調査支援などで利用が広がっている。
2. 記事で扱うべき内容
- AIエージェントの定義
- 従来のチャットAIとの違い
- 業務活用例
- 導入時の注意点
- 人間による確認の必要性
3. 注意点
- 最新情報は変化が早いため、特定サービス名や料金を断定しすぎない。
- 出典が不明な情報は使用しない。
4. 参考URL
- https://...
- https://...Writer AIは、この調査メモを参考に記事を書きます。
このとき重要なのは、Researcher AIに「検索結果をそのまま貼り付けさせない」ことです。
検索結果を整理し、記事で使いやすい情報に変換する役割を持たせます。
Writer AIへの渡し方
第6回AI記事作成では、Writer AIに渡す情報が増えます。
第5回までは、主に以下でした。
キーワード
記事設計
レビュー指摘
前回ドラフト第6回では、ここに調査メモを追加します。
キーワード
記事設計
調査メモ
レビュー指摘
前回ドラフトつまり、run_writer() の引数に research_note を追加します。
イメージは以下です。
article = run_writer(
keyword=keyword,
plan=plan,
research_note=research_note,
)修正時にも、調査メモを維持したままWriter AIへ渡します。
article = run_writer(
keyword=keyword,
plan=plan,
research_note=research_note,
review=review_for_writer,
previous_draft=article,
)これにより、Writer AIは最新情報や参考情報を踏まえた記事を書けるようになります。
Web検索結果をそのまま信じない
Brave Search APIを使うと、検索結果を構造化されたJSONで取得できます。
しかし、検索APIを使っても、Web検索結果が常に正しいとは限りません。
・古い情報が上位に出る
・信頼性の低いサイトが混ざる
・広告や転載記事が混ざる
・一次情報ではない場合がある
・同じ情報が複数サイトに転載されている場合があるそのため、Researcher AIには次のようなルールを与えます。
・公式サイトや一次情報を優先する
・複数の情報源を確認する
・出典URLを残す
・不確かな情報は断定しない
・日付が重要な情報は更新日を確認する
・Writer AIには「確実な情報」と「注意が必要な情報」を分けて渡す特に、AIモデル、料金、サービス仕様、リリース情報などは変化が早いため、検索結果の扱いには注意が必要です。
第6回AI記事作成で追加・変更となるファイル
第6回AI記事作成では、以下の6ファイルが追加・変更となります。
追加:
・agents/researcher.py
・web_search_tool.py
変更:
・main.py
・agents/writer.py
・mcp_client.py
・mcp_server.py
追加:web_search_tool.py
import json
import os
import urllib.parse
import urllib.request
BRAVE_SEARCH_ENDPOINT = "https://api.search.brave.com/res/v1/web/search"
def web_search(query: str, max_results: int = 5) -> dict:
"""
Brave Search APIを使ってWeb検索を行う疑似MCPツール。
事前に環境変数 BRAVE_SEARCH_API_KEY を設定してください。
例:
export BRAVE_SEARCH_API_KEY="your_api_key"
"""
api_key = os.getenv("BRAVE_SEARCH_API_KEY")
if not api_key:
return {
"status": "error",
"tool": "web_search",
"provider": "brave_search_api",
"query": query,
"message": "環境変数 BRAVE_SEARCH_API_KEY が設定されていません。",
"results": [],
}
if not query.strip():
return {
"status": "error",
"tool": "web_search",
"provider": "brave_search_api",
"query": query,
"message": "検索クエリが空です。",
"results": [],
}
params = urllib.parse.urlencode(
{
"q": query,
"count": max_results,
}
)
url = f"{BRAVE_SEARCH_ENDPOINT}?{params}"
request = urllib.request.Request(
url,
headers={
"Accept": "application/json",
"X-Subscription-Token": api_key,
"User-Agent": "Mozilla/5.0",
},
)
try:
with urllib.request.urlopen(request, timeout=20) as response:
raw_body = response.read().decode("utf-8", errors="ignore")
data = json.loads(raw_body)
except Exception as error:
return {
"status": "error",
"tool": "web_search",
"provider": "brave_search_api",
"query": query,
"message": f"Brave Search APIでの検索に失敗しました: {error}",
"results": [],
}
web_results = data.get("web", {}).get("results", [])
results = []
for item in web_results[:max_results]:
results.append(
{
"title": item.get("title", ""),
"url": item.get("url", ""),
"snippet": item.get("description", ""),
}
)
return {
"status": "ok",
"tool": "web_search",
"provider": "brave_search_api",
"query": query,
"results": results,
}
def web_search_results_to_text(search_results: list[dict]) -> str:
"""
検索結果をResearcher AIへ渡しやすいテキスト形式に変換する。
"""
lines = []
for index, item in enumerate(search_results, start=1):
query = item.get("query", "")
status = item.get("status", "")
provider = item.get("provider", "")
message = item.get("message", "")
results = item.get("results", [])
lines.append(f"## 検索クエリ {index}: {query}")
lines.append(f"status: {status}")
if provider:
lines.append(f"provider: {provider}")
if message:
lines.append(f"message: {message}")
lines.append("")
if not results:
lines.append("- 検索結果なし")
lines.append("")
continue
for result_index, result in enumerate(results, start=1):
lines.append(f"{result_index}. {result.get('title', '')}")
lines.append(f"URL: {result.get('url', '')}")
snippet = result.get("snippet", "")
if snippet:
lines.append(f"概要: {snippet}")
lines.append("")
return "\n".join(lines)
def web_search_results_to_json(search_results: list[dict]) -> str:
"""
検索結果を保存用JSON文字列へ変換する。
"""
return json.dumps(search_results, ensure_ascii=False, indent=2)追加:agents/researcher.py
import json
from llm_client import call_gemma4
def _extract_json_array(text: str) -> list[str]:
"""
LLMの出力からJSON配列を取り出す。
失敗した場合は空リストを返す。
"""
text = text.replace("```json", "")
text = text.replace("```JSON", "")
text = text.replace("```", "")
text = text.strip()
first_bracket = text.find("[")
last_bracket = text.rfind("]")
if first_bracket == -1 or last_bracket == -1 or last_bracket <= first_bracket:
return []
json_text = text[first_bracket : last_bracket + 1]
try:
data = json.loads(json_text)
except json.JSONDecodeError:
return []
if not isinstance(data, list):
return []
queries = []
for item in data:
if isinstance(item, str) and item.strip():
queries.append(item.strip())
return queries
def create_research_queries(keyword: str, plan: str) -> list[str]:
"""
Researcher AI:
記事キーワードと記事設計から、Brave Search API用の検索クエリを作成する。
"""
system_prompt = """
あなたは記事作成のためのResearcher AIです。
入力されたキーワードと記事設計をもとに、Web検索に使う検索クエリを作成してください。
重要:
・検索クエリは3〜5個にしてください。
・入力キーワードに年が含まれる場合、その年を優先して検索クエリに含めてください。
・最新情報が必要な場合は「最新」「公式」「発表」「比較」「動向」などを含めてください。
・信頼性の高い情報を探しやすいクエリにしてください。
・検索APIに渡しやすい短めの検索語にしてください。
・出力はJSON配列のみとしてください。
・コードブロック記号は使わないでください。
"""
user_prompt = f"""
以下のキーワードと記事設計をもとに、Web検索用クエリをJSON配列で作成してください。
キーワード:
{keyword}
記事設計:
{plan}
条件:
・キーワードに含まれる年や主題を勝手に変更しないでください。
・「最新AIモデル」が主題の場合、AIモデル名、基盤モデル、LLM、マルチモーダル、AIエージェントなどを調べやすい検索クエリにしてください。
・公式発表や信頼性の高い情報源に近づける検索クエリを含めてください。
出力例:
[
"2026年 最新AIモデル 比較",
"2026 AI model trends official",
"基盤モデル LLM マルチモーダル AIエージェント 最新"
]
"""
response = call_gemma4(system_prompt, user_prompt)
queries = _extract_json_array(response)
if queries:
return queries[:5]
# LLM出力が崩れた場合のフォールバック
return [
f"{keyword} 最新",
f"{keyword} 公式",
f"{keyword} 比較",
]
def run_researcher(keyword: str, plan: str, search_results_text: str) -> str:
"""
Researcher AI:
Brave Search APIの検索結果をもとに、Writer AIへ渡す調査メモを作成する。
"""
system_prompt = """
あなたは記事作成のためのResearcher AIです。
Web検索結果を読み、Writer AIが記事作成に使いやすい調査メモを作成してください。
最重要ルール:
・検索結果の title / URL / 概要 を必ず根拠として使ってください。
・参考URL一覧を必ず作成してください。
・検索結果にURLがある場合、最低3件以上のURLを列挙してください。
・検索結果にない事実、モデル名、数値、リリース情報を断定しないでください。
・入力キーワードに含まれる年や主題を勝手に変更しないでください。
・キーワードが「2026年」の場合、見出しやタイトル案を勝手に「2025年」に変更しないでください。
・不確かな情報は「検索結果だけでは確認できない」と明記してください。
・検索結果をそのまま貼り付けるのではなく、記事で使える調査メモに整理してください。
調査メモの目的:
・Writer AIが、検索結果に基づいて記事を書けるようにすること。
・一般論ではなく、検索結果から確認できた論点を渡すこと。
・検索結果に含まれる情報と、推測や補足を明確に分けること。
"""
user_prompt = f"""
以下のキーワード、記事設計、Web検索結果をもとに、Writer AIへ渡す調査メモを作成してください。
キーワード:
{keyword}
記事設計:
{plan}
Web検索結果:
{search_results_text}
出力形式:
# 調査メモ
## 1. 検索結果から確認できた事実
検索結果の title / URL / 概要 をもとに、確認できた事実を箇条書きで整理してください。
各項目には、できるだけ参照元URLを添えてください。
## 2. 記事に反映すべき重要ポイント
Writer AIが記事本文に反映すべきポイントを整理してください。
入力キーワードから外れた内容に広げすぎないでください。
## 3. 参考URL一覧
検索結果に含まれるURLを最低3件以上列挙してください。
URLがある場合は必ずそのまま出力してください。
## 4. 検索結果だけでは不足している点
検索結果だけでは確認できないこと、断定してはいけないことを整理してください。
## 5. Writer AIへの具体的な指示
Writer AIが記事を書くときの注意点を整理してください。
必ず以下を含めてください。
・記事タイトルには入力キーワードを自然に含める
・検索結果に出てきた主要論点を反映する
・検索結果にない最新情報やモデル名を断定しない
・年の表記を入力キーワードと矛盾させない
・出典URLを参考リンクとして記事内または記事末尾に残す
禁止事項:
・検索結果にURLがあるのに、参考URL一覧を省略すること
・入力キーワードが2026年なのに、タイトル案を2025年にすること
・検索結果にない具体的なモデル名や数値を断定すること
・単なる一般論だけの構成案にすること
"""
return call_gemma4(system_prompt, user_prompt)変更:mcp_server.py
from pathlib import Path
from web_search_tool import web_search as tool_web_search
def save_text_file(filepath: str, content: str) -> dict:
"""
指定されたパスにテキストファイルを保存する疑似MCPツール。
plan.txt / draft_1.html / review_1.txt / validation_1.txt など、
任意の途中結果を保存できる。
"""
path = Path(filepath)
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(content, encoding="utf-8")
return {
"status": "ok",
"tool": "save_text_file",
"path": str(path),
}
def save_article(run_dir: str, content: str, filename: str = "final_article.html") -> dict:
"""
最終記事を保存する疑似MCPツール。
"""
filepath = Path(run_dir) / filename
result = save_text_file(str(filepath), content)
return {
"status": result["status"],
"tool": "save_article",
"path": result["path"],
}
def save_run_summary(run_dir: str, content: str, filename: str = "run_summary.txt") -> dict:
"""
実行結果の概要を保存する疑似MCPツール。
"""
filepath = Path(run_dir) / filename
result = save_text_file(str(filepath), content)
return {
"status": result["status"],
"tool": "save_run_summary",
"path": result["path"],
}
def read_text_file(filepath: str) -> dict:
"""
指定されたテキストファイルを読み込む疑似MCPツール。
"""
path = Path(filepath)
if not path.exists():
return {
"status": "error",
"tool": "read_text_file",
"path": str(path),
"message": "file not found",
"content": "",
}
content = path.read_text(encoding="utf-8")
return {
"status": "ok",
"tool": "read_text_file",
"path": str(path),
"content": content,
}
def web_search(query: str, max_results: int = 5) -> dict:
"""
Brave Search APIを使ってWeb検索を行う疑似MCPツール。
第6回では、正式MCPではなく、
Python関数でWeb検索ツールを呼び出す疑似MCP構成として扱う。
"""
return tool_web_search(query=query, max_results=max_results)変更:mcp_client.py
from mcp_server import save_text_file as tool_save_text_file
from mcp_server import save_article as tool_save_article
from mcp_server import save_run_summary as tool_save_run_summary
from mcp_server import read_text_file as tool_read_text_file
from mcp_server import web_search as tool_web_search
def save_text_file(filepath: str, content: str) -> dict:
"""
任意のテキストファイル保存用の呼び出し口。
"""
return tool_save_text_file(filepath, content)
def save_article(run_dir: str, content: str, filename: str = "final_article.html") -> dict:
"""
最終記事保存用の呼び出し口。
"""
return tool_save_article(run_dir, content, filename)
def save_run_summary(run_dir: str, content: str, filename: str = "run_summary.txt") -> dict:
"""
実行結果サマリー保存用の呼び出し口。
"""
return tool_save_run_summary(run_dir, content, filename)
def read_text_file(filepath: str) -> dict:
"""
保存済みテキストファイル読み込み用の呼び出し口。
"""
return tool_read_text_file(filepath)
def web_search(query: str, max_results: int = 5) -> dict:
"""
Web検索用の呼び出し口。
main.py からはこの関数を呼び、
実際のBrave Search API処理は web_search_tool.py 側で行う。
"""
return tool_web_search(query=query, max_results=max_results)変更:agents/writer.py
from llm_client import call_gemma4
def run_writer(
keyword: str,
plan: str,
research_note: str | None = None,
review: str | None = None,
previous_draft: str | None = None,
) -> str:
"""
Writer AI:
Planner AIの設計とResearcher AIの調査メモに沿って記事を作成する。
Reviewer AIまたはPython側チェックの指摘がある場合は、前回の記事を修正する。
"""
system_prompt = """
あなたはSEO記事を作成するWriter AIです。
Planner AIの設計とResearcher AIの調査メモに沿って、読みやすく分かりやすい日本語記事をHTML形式で作成してください。
重要な出力ルール:
・HTML断片として出力する
・html、head、bodyタグは出力しない
・styleタグ、CSS、JavaScriptは出力しない
・Markdown記法は使わない
・コードブロック記号 ``` は出力しない
・見出しは h2 / h3 を使う
・本文は p タグを使う
・箇条書きは ul / li を使う
・表が必要な場合は table / tr / th / td を使う
・誇張表現を避ける
・初心者にも理解しやすい文章にする
・根拠のない最新情報や未確認情報は断定しない
・調査メモに含まれる出典や注意点を尊重する
・調査メモにない最新情報を推測で追加しない
・本文を省略しない
・「ここに挿入」「省略」「以下略」などのプレースホルダーを使わない
SEOと検索意図に関する重要ルール:
・記事タイトルには、入力キーワードを自然な形で必ず含める
・入力キーワードに年が含まれる場合、その年をタイトル・導入文・主要見出しのいずれかに必ず反映する
・入力キーワードに「2026年」が含まれる場合、「202X年」「2025年」などに置き換えない
・入力キーワードの主題から外れた一般論に広げすぎない
・「最新AIモデル」「AIモデルのトレンド」が主題の場合、モデルや技術トレンドの分類を必ず含める
・具体的なモデル名やリリース情報は、調査メモに根拠がある場合のみ扱う
・調査メモに参考URLがある場合、記事末尾に「参考リンク」または「参考情報」セクションを作る
・参考リンクには、調査メモに含まれるURLをそのまま記載する
・参考URLがあるにもかかわらず、参考リンク一覧を省略しない
"""
research_block = research_note or "調査メモはありません。"
if review and previous_draft:
user_prompt = f"""
以下の記事を、Reviewer AIまたはPython側チェックの指摘に従って修正してください。
キーワード:
{keyword}
記事設計:
{plan}
Researcher AIの調査メモ:
{research_block}
修正前の記事:
{previous_draft}
修正指示:
{review}
修正条件:
・修正前の記事本文を維持しながら、必要な箇所だけ改善する
・記事本文を削除しない
・記事本文をプレースホルダーに置き換えない
・「ここに挿入」「省略」「以下略」などを使わない
・必ず修正後の記事全文を出力する
・前回の記事の本文量を大きく減らさない
・HTML断片として出力する
・html、head、bodyタグは出力しない
・styleタグ、CSS、JavaScriptは出力しない
・Markdown記法は使わない
・コードブロック記号 ``` は出力しない
・h2 / h3 / p / ul / li / table などのHTMLタグで整理する
・SEOタイトル、メタディスクリプション、AI要約ブロック、本文、FAQ、まとめを含める
・調査メモにない最新情報を推測で追加しない
キーワード・年表記・参考URLに関する修正条件:
・記事タイトルには、入力キーワード「{keyword}」を自然な形で含める
・入力キーワードに含まれる年を勝手に変更しない
・「202X年」のような曖昧な年表記は使わない
・キーワードが2026年を含む場合、タイトル・導入文・主要見出しのいずれかに2026年を明記する
・入力キーワードの主題から外れた一般論に広げすぎない
・「最新AIモデル」「AIモデルのトレンド」が主題の場合、以下のような技術分類を本文に含める
- マルチモーダルAI
- AIエージェント
- エッジAIまたはローカルLLM
- 高効率化、小型化、推論性能の進化
- AIガバナンスや説明可能性
・Researcher AIの調査メモに参考URLが含まれている場合、記事末尾に「参考リンク」セクションを追加する
・参考リンクには、調査メモに含まれるURLをそのまま記載する
・参考URLがあるのに省略しない
"""
else:
user_prompt = f"""
以下の記事設計と調査メモをもとに、SEO記事をHTML形式で作成してください。
キーワード:
{keyword}
記事設計:
{plan}
Researcher AIの調査メモ:
{research_block}
出力条件:
・HTML断片として出力する
・html、head、bodyタグは出力しない
・styleタグ、CSS、JavaScriptは出力しない
・Markdown記法は使わない
・コードブロック記号 ``` は出力しない
・SEOタイトルを含める
・メタディスクリプションを含める
・AI要約ブロックを含める
・h2/h3構成に沿った本文を作成する
・FAQを含める
・まとめを含める
・本文を省略しない
・プレースホルダーを使わない
・調査メモにない最新情報を推測で追加しない
キーワード・年表記・参考URLに関する出力条件:
・記事タイトルには、入力キーワード「{keyword}」を自然な形で必ず含める
・入力キーワードに含まれる年を勝手に変更しない
・「202X年」のような曖昧な年表記は使わない
・キーワードが2026年を含む場合、タイトル・導入文・主要見出しのいずれかに2026年を明記する
・入力キーワードの主題から外れた一般論に広げすぎない
・「最新AIモデル」「AIモデルのトレンド」が主題の場合、以下のような技術分類を本文に含める
- マルチモーダルAI
- AIエージェント
- エッジAIまたはローカルLLM
- 高効率化、小型化、推論性能の進化
- AIガバナンスや説明可能性
・Researcher AIの調査メモに参考URLが含まれている場合、記事末尾に「参考リンク」セクションを追加する
・参考リンクには、調査メモに含まれるURLをそのまま記載する
・参考URLがあるのに省略しない
"""
return call_gemma4(system_prompt, user_prompt)変更:main.py
from datetime import datetime
import re
from agents.planner import run_planner
from agents.researcher import create_research_queries, run_researcher
from agents.writer import run_writer
from agents.reviewer import run_reviewer
from mcp_client import save_text_file, save_article, save_run_summary, web_search
from validators import validate_html_fragment, sanitize_html_fragment
from web_search_tool import web_search_results_to_text, web_search_results_to_json
from review_parser import (
parse_review_result,
review_result_to_text,
build_review_json_feedback,
build_unknown_review_feedback,
)
MAX_REVIEW_LOOPS = 3
MAX_SEARCH_RESULTS_PER_QUERY = 3
def slugify_keyword(keyword: str) -> str:
"""
フォルダ名に使いやすいようにキーワードを簡易変換する。
日本語はそのまま残し、使いにくい記号だけ置き換える。
"""
slug = keyword.strip()
slug = re.sub(r"\s+", "_", slug)
slug = re.sub(r'[\\/:*?"<>|]', "_", slug)
if not slug:
slug = "article"
return slug[:40]
def build_validation_text(issues: list[str]) -> str:
"""
Python側チェック結果を保存用テキストに変換する。
"""
if not issues:
return "Python側HTMLチェック:OK\n"
lines = [
"Python側HTMLチェック:修正必要",
"",
]
for issue in issues:
lines.append(f"- {issue}")
return "\n".join(lines)
def build_validation_review(issues: list[str]) -> str:
"""
Python側チェックで見つかった問題を、
Writer AIに渡せるレビュー文に変換する。
"""
issue_text = "\n".join(f"- {issue}" for issue in issues)
return f"""
Python側のHTML形式チェックで、以下の問題が見つかりました。
{issue_text}
Writer AIへの修正指示:
・上記の問題をすべて修正してください。
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
status:
VALIDATION_FAILED
"""
def main():
print("Gemma 4ローカル・マルチエージェント記事作成システム")
print("-" * 50)
keyword = input("記事キーワードを入力してください: ").strip()
if not keyword:
print("キーワードが入力されていません。終了します。")
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
keyword_slug = slugify_keyword(keyword)
run_dir = f"output/{timestamp}_{keyword_slug}"
print(f"\n実行結果フォルダ: {run_dir}")
print("\n[1] Planner AI が記事設計を作成中...")
plan = run_planner(keyword)
save_text_file(f"{run_dir}/plan.txt", plan)
print("\n[2] Researcher AI が検索クエリを作成中...")
research_queries = create_research_queries(keyword=keyword, plan=plan)
research_query_text = "\n".join(f"- {query}" for query in research_queries)
save_text_file(f"{run_dir}/research_query.txt", research_query_text)
print("\n--- Researcher AI の検索クエリ ---")
print(research_query_text)
print("--- 検索クエリここまで ---")
print("\n[3] Brave Search APIでWeb検索中...")
all_search_results = []
for query in research_queries:
print(f"- 検索中: {query}")
result = web_search(query=query, max_results=MAX_SEARCH_RESULTS_PER_QUERY)
all_search_results.append(result)
search_results_json = web_search_results_to_json(all_search_results)
search_results_text = web_search_results_to_text(all_search_results)
save_text_file(f"{run_dir}/web_search_results.json", search_results_json)
print("\n[4] Researcher AI が調査メモを作成中...")
research_note = run_researcher(
keyword=keyword,
plan=plan,
search_results_text=search_results_text,
)
save_text_file(f"{run_dir}/research_note.txt", research_note)
print("\n--- Researcher AI の調査メモ ---")
print(research_note)
print("--- 調査メモここまで ---")
print("\n[5] Writer AI が初稿を作成中...")
article = run_writer(
keyword=keyword,
plan=plan,
research_note=research_note,
)
article = sanitize_html_fragment(article)
save_text_file(f"{run_dir}/draft_1.html", article)
latest_review = ""
latest_review_result = {
"status": "UNKNOWN",
"summary": "まだレビューは実行されていません。",
"issues": [],
"next_action": "RETRY_REVIEW",
}
review_passed = False
final_review_status = "UNKNOWN"
final_validation_issues: list[str] = []
for loop_count in range(1, MAX_REVIEW_LOOPS + 1):
print(f"\n[6] Reviewer AI がレビュー中... ({loop_count}/{MAX_REVIEW_LOOPS})")
latest_review = run_reviewer(keyword=keyword, draft=article)
save_text_file(f"{run_dir}/review_{loop_count}.txt", latest_review)
print("\n--- Reviewer AI のレビュー結果 ---")
print(latest_review)
print("--- レビュー結果ここまで ---")
latest_review_result = parse_review_result(latest_review)
final_review_status = latest_review_result["status"]
save_text_file(
f"{run_dir}/review_result_{loop_count}.json",
review_result_to_text(latest_review_result),
)
print("\n--- Reviewer AI の判定JSON ---")
print(review_result_to_text(latest_review_result))
print("--- 判定JSONここまで ---")
if final_review_status == "UNKNOWN":
print("\nReviewer AI の判定JSONが不明です。修正必要として扱います。")
article = sanitize_html_fragment(article)
validation_issues = validate_html_fragment(article)
final_validation_issues = validation_issues
validation_text = build_validation_text(validation_issues)
save_text_file(f"{run_dir}/validation_{loop_count}.txt", validation_text)
if validation_issues:
print("\nPython側HTMLチェック:修正必要")
for issue in validation_issues:
print(f"- {issue}")
if final_review_status == "OK" and not validation_issues:
print("\nReviewer AI JSON判定 + Python側HTMLチェック の判定:OK")
review_passed = True
break
print("\n判定:修正必要")
if loop_count == MAX_REVIEW_LOOPS:
print("\n最大レビュー回数に達しました。これ以上修正せず、最後に検証済みの記事を保存します。")
break
if validation_issues:
review_for_writer = build_validation_review(validation_issues)
elif final_review_status == "REVISION_REQUIRED":
review_for_writer = build_review_json_feedback(latest_review_result)
else:
review_for_writer = build_unknown_review_feedback(latest_review, latest_review_result)
print(f"\n[7] Writer AI がレビュー指摘に従って修正中... ({loop_count}/{MAX_REVIEW_LOOPS})")
article = run_writer(
keyword=keyword,
plan=plan,
research_note=research_note,
review=review_for_writer,
previous_draft=article,
)
article = sanitize_html_fragment(article)
next_draft_number = loop_count + 1
save_text_file(f"{run_dir}/draft_{next_draft_number}.html", article)
print("\n[8] 最終HTMLを保存中...")
article = sanitize_html_fragment(article)
result = save_article(run_dir, article)
status_text = "OK判定後に保存" if review_passed else "最大レビュー回数到達後に保存"
if final_validation_issues:
validation_summary = "\n".join(f"- {issue}" for issue in final_validation_issues)
else:
validation_summary = "Python側HTMLチェック:OK"
review_json_summary = review_result_to_text(latest_review_result)
summary = f"""実行キーワード:{keyword}
保存状態:{status_text}
Reviewer最終JSON判定:{final_review_status}
最終保存先:{result['path']}
レビュー最大回数:{MAX_REVIEW_LOOPS}
実行結果フォルダ:{run_dir}
検索クエリ:
{research_query_text}
最終Reviewer判定JSON:
{review_json_summary}
最終Python側HTMLチェック:
{validation_summary}
"""
save_run_summary(run_dir, summary)
print("\n完了しました。")
print(f"保存先: {result['path']}")
if review_passed:
print("保存状態:Reviewer AI のJSON判定とPython側HTMLチェックのOK後に保存しました。")
else:
print("保存状態:最大レビュー回数に達したため、最後の記事を保存しました。")
print(f"Reviewer最終JSON判定:{final_review_status}")
if __name__ == "__main__":
main()第6回AI記事作成の処理途中で保存するファイル
第6回でも、途中保存の仕組みは維持します。
さらに、Researcher AI関連のファイルを追加します。
plan.txt
research_query.txt
web_search_results.json
research_note.txt
draft_1.html
review_1.txt
review_result_1.json
validation_1.txt
final_article.html
run_summary.txtそれぞれの意味は以下です。
| ファイル | 内容 |
|---|---|
plan.txt | Planner AIの記事設計 |
research_query.txt | Researcher AIが作成した検索クエリ |
web_search_results.json | Brave Search APIから取得した検索結果 |
research_note.txt | Researcher AIが整理した調査メモ |
draft_1.html | Writer AIの初稿 |
review_1.txt | Reviewer AIの自然文レビュー |
review_result_1.json | Reviewer AIの判定JSON |
validation_1.txt | Python側HTMLチェック結果 |
final_article.html | 最終記事 |
run_summary.txt | 実行概要 |
これにより、記事がどの情報をもとに作られたのか追跡しやすくなります。
第6回AI記事作成でできること
第6回AI記事作成では、以下の機能を持ちます。
・Researcher AIを追加する
・Brave Search APIを使ったWeb検索MCP風ツールを追加する
・検索結果をJSON形式で取得する
・検索結果を調査メモに整理する
・Writer AIが調査メモをもとに記事を書く
・最新情報を扱う記事に対応しやすくする
・検索結果や調査メモも途中保存するここまでできると、ローカルAI記事作成システムは、単なる文章生成ツールではなく、調査・執筆・レビュー・検証を分担するマルチエージェント構成に近づきます。
第6回AI記事作成の実行と実行結果
Brave Search APIキーの設定
環境変数を利用する場合
設定
export BRAVE_SEARCH_API_KEY="ここに取得したAPIキー"確認
echo $BRAVE_SEARCH_API_KEY.bashrcを利用する場合
設定
echo 'export BRAVE_SEARCH_API_KEY="ここに取得したAPIキー"' >> ~/.bashrc.bashrc は、Bashが起動するたびに読み込む設定ファイル
最新の状態に更新
source ~/.bashrcプログラムの実行
python main.py実行結果
ターミナル出力
(UTF-8)
(SHIFT-JIS)
作成記事
(UTF-8)
(SHIFT-JIS)
第6回では、Planner AI、Writer AI、Reviewer AIに加えて、Researcher AIを追加しました。
Researcher AIは、記事を書く前に検索クエリを作成し、Brave Search APIを使ったWeb検索MCP風ツールから検索結果を受け取り、Writer AIへ渡す調査メモを作成します。
これにより、ローカルLLMだけでは不足しやすい最新情報を、記事作成フローに取り込めるようになりました。
まだ参考URLの本文反映など改善余地はありますが、Researcher AIを含む調査・執筆・レビュー・検証の流れは一通り動作しました。
まとめ:Brave Search APIでローカルLLMの弱点を補う
第6回AI記事作成では、Planner AI、Writer AI、Reviewer AIに加えて、Researcher AIを追加する流れを整理しました。
ローカルLLMは便利ですが、単体では最新情報を取得できません。
そこで、Brave Search APIを使ったWeb検索MCP風ツールを使い、Researcher AIが検索結果を整理してWriter AIへ渡す構成にします。
Brave Search API
↓
Researcher AI
↓
調査メモ
↓
Writer AIこの流れにより、AI記事作成システムは、最新情報を扱う記事にも対応しやすくなります。
ただし、検索APIを使っても、検索結果をそのまま信じるのではなく、Researcher AIが出典や信頼性を整理し、Writer AIには調査メモとして渡すことが重要です。
第6回AI記事作成は、ローカルAIマルチエージェント記事作成システムを、調査もできる記事作成システムへ発展させる回でした。
第7回では、イベントに応じて各AIエージェントやツールを呼び出す構成へ進めます。
第7回:イベント駆動型マルチエージェントへ発展させる

