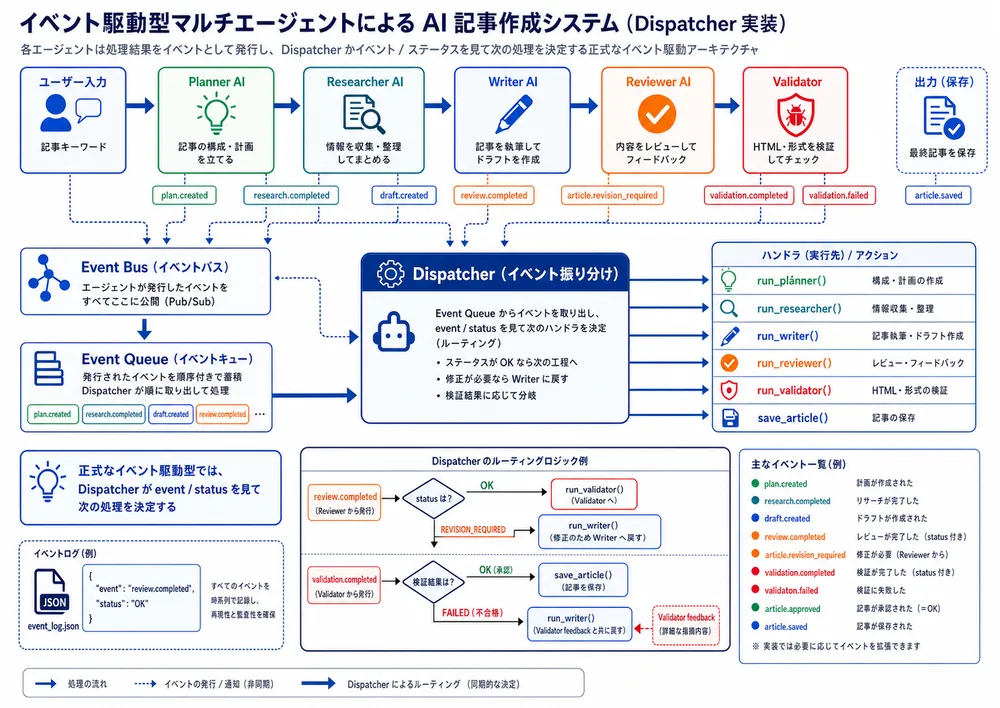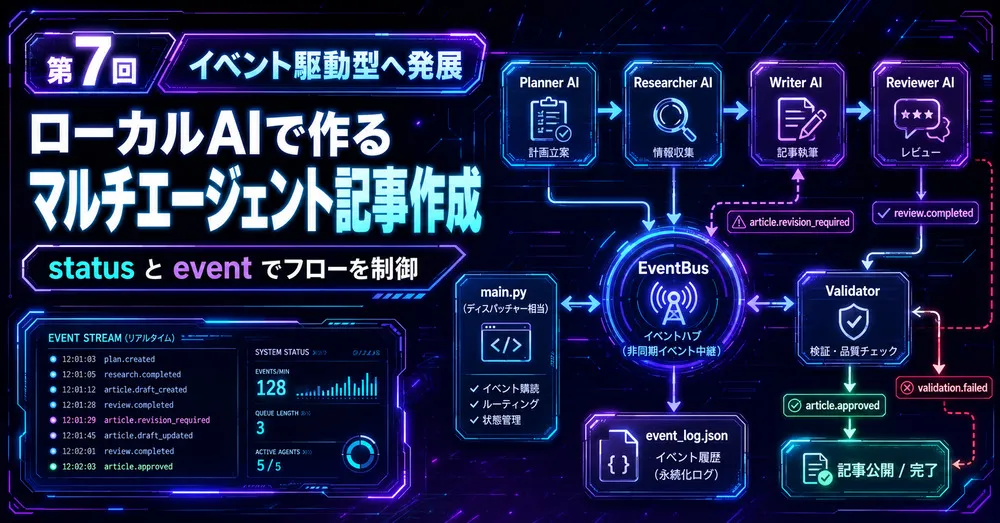
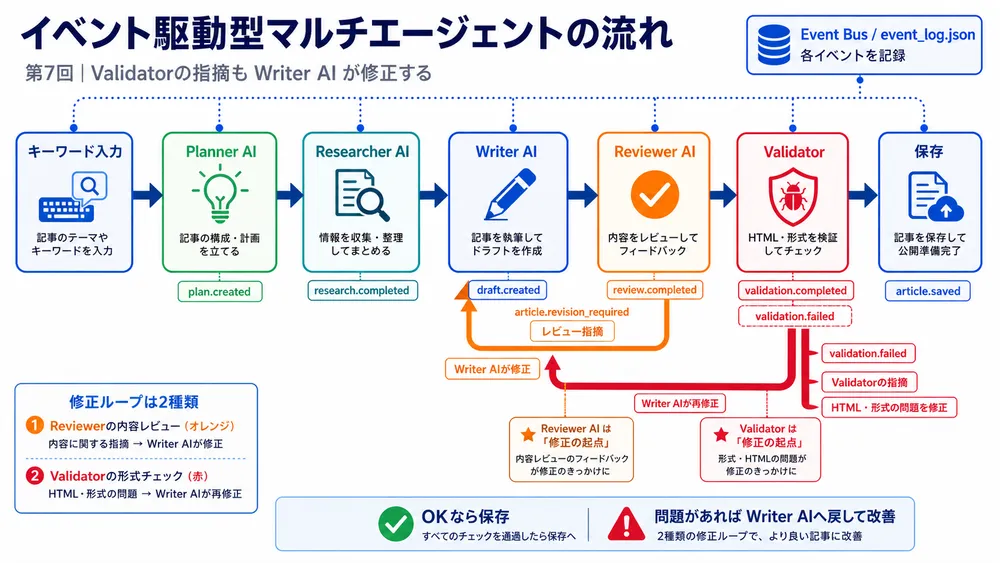
第7回では、これまで順番に実行していたAI記事作成フローを、イベント駆動型の考え方で整理します。
Reviewer AIのJSON判定やPython側HTMLチェックの結果を status として扱い、article.revision_required、validation.failed、article.approved などのイベントに変換します。
これにより、AIエージェント同士の処理を追跡しやすくなり、将来的なDispatcher実装や正式なイベント駆動システムへ発展させやすくなります。
第6回AI記事作成まででできたこと
第6回AI記事作成では、Planner AI、Writer AI、Reviewer AIに加えて、Researcher AI を追加しました。
Researcher AIは、記事を書く前に検索クエリを作成し、Brave Search APIを使ったWeb検索MCP風ツールから検索結果を受け取り、Writer AIへ渡す調査メモを作成しました。
これにより、ローカルLLMだけでは不足しやすい最新情報を、記事作成フローに取り込めるようになりました。
第6回AI記事作成までの流れは、次のような順番実行型です。
Planner AI
↓
Researcher AI
↓
Writer AI
↓
Reviewer AI
↓
Python側HTMLチェック
↓
保存この形は分かりやすく、学習にも向いています。
ただし、エージェントが増えるほど、main.py が大きくなりやすいという問題があります。
そこで第7回AI記事作成では、処理を イベント駆動型 の考え方で整理します。
イベント駆動型とは
イベント駆動型とは、簡単にいうと、何かが起きたら、それに応じて次の処理を実行する仕組みです。
これまでの処理では、main.py が順番に各処理を呼んでいました。
main.pyが順番に呼ぶ
↓
Planner AI
↓
Researcher AI
↓
Writer AI
↓
Reviewer AI
↓
Validator
↓
保存イベント駆動型では、処理結果をイベントとして扱います。
plan.created
↓
research.completed
↓
draft.created
↓
review.completed
↓
validation.completed
↓
article.approved
↓
article.savedつまり、処理を単なる順番ではなく、状態の変化として見る考え方です。
イベント駆動型にする理由
イベント駆動型にする理由は、マルチエージェント構成が大きくなったときに管理しやすくするためです。
第6回までの構成では、main.py が多くの判断を持っています。
・次にどのAIを呼ぶか
・レビュー結果がOKか
・修正が必要か
・HTMLチェックが通ったか
・保存するか
・最大レビュー回数に達したかこの判断が増えると、main.py が複雑になります。
イベント駆動型では、次のように整理します。
何が起きたか
↓
どのeventか
↓
statusは何か
↓
次に実行する処理を決めるたとえば、Reviewer AIがOKを出した場合は、次のように考えます。
review.completed
↓
status = OK
↓
Validatorへ進む一方で、Reviewer AIが修正必要と判断した場合は、次のようになります。
review.completed
↓
status = REVISION_REQUIRED
↓
Writer AIへ戻して修正第5回AI記事作成のJSON判定の利用
第7回AI記事作成で重要になるのが、第5回で実装したReviewer AIのJSON判定です。
第5回では、Reviewer AIの自然文レビューとは別に、次のようなJSONを出力させました。
{
"status": "OK",
"summary": "記事構成とHTML形式に大きな問題はありません。",
"issues": [],
"next_action": "SAVE"
}この status と next_action は、イベント駆動型にそのまま使えます。
status: OK
↓
article.approved
status: REVISION_REQUIRED
↓
article.revision_required
status: UNKNOWN
↓
review.failedつまり、第5回でJSON化したことは、第7回でイベント駆動型へ進むための準備だったといえます。
第7回AI記事作成で使うイベント例
第7回では、まず次のようなイベントを使います。
plan.created
research.completed
draft.created
draft.revised
review.completed
article.revision_required
validation.completed
validation.failed
article.approved
article.savedそれぞれの意味は次の通りです。
| イベント名 | 意味 |
|---|---|
plan.created | Planner AIが記事設計を作成した |
research.completed | Researcher AIが調査メモを作成した |
draft.created | Writer AIが初稿を作成した |
draft.revised | Writer AIが修正版を作成した |
review.completed | Reviewer AIがレビューを完了した |
article.revision_required | Reviewer AIにより修正が必要と判断された |
validation.completed | Python側チェックが完了した |
validation.failed | Python側チェックで問題が見つかった |
article.approved | 記事が公開可能と判断された |
article.saved | 最終記事が保存された |
このようにイベント名を決めておくと、あとから処理を追加しやすくなります。
修正ループは2種類ある
第7回AI記事作成では、修正ループを2種類に分けて考えます。
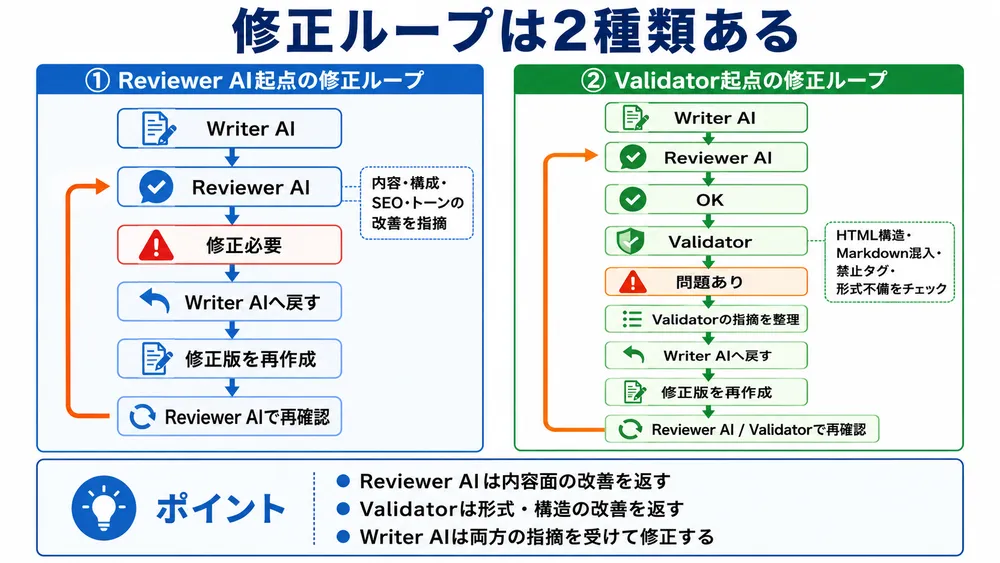
1つ目は、Reviewer AI起点の修正ループです。
Writer AI
↓
Reviewer AI
↓
修正必要
↓
Writer AIへ戻すReviewer AIは、主に次のような観点を見ます。
・記事構成
・読みやすさ
・SEO観点
・トーン
・内容の不足
・検索意図とのズレ2つ目は、Validator起点の修正ループです。
Writer AI
↓
Reviewer AI
↓
OK
↓
Validator
↓
問題あり
↓
Writer AIへ戻すValidatorは、主に次のような機械的・形式的な問題を見ます。
・HTML断片として正しいか
・styleタグやscriptタグがないか
・Markdown記法が残っていないか
・pタグやh2タグがあるか
・プレースホルダーが残っていないか
・不自然なHTMLタグがないかつまり、第7回では次のように整理できます。
Reviewer AI
→ 内容の改善点を返す
Validator
→ 形式・構造の改善点を返す
Writer AI
→ 両方の指摘を受けて修正する処理の流れをイベントで置き換える
イベント駆動型マルチエージェントに向けて、第6回AI記事作成までの流れをイベントを使って置き換えます。
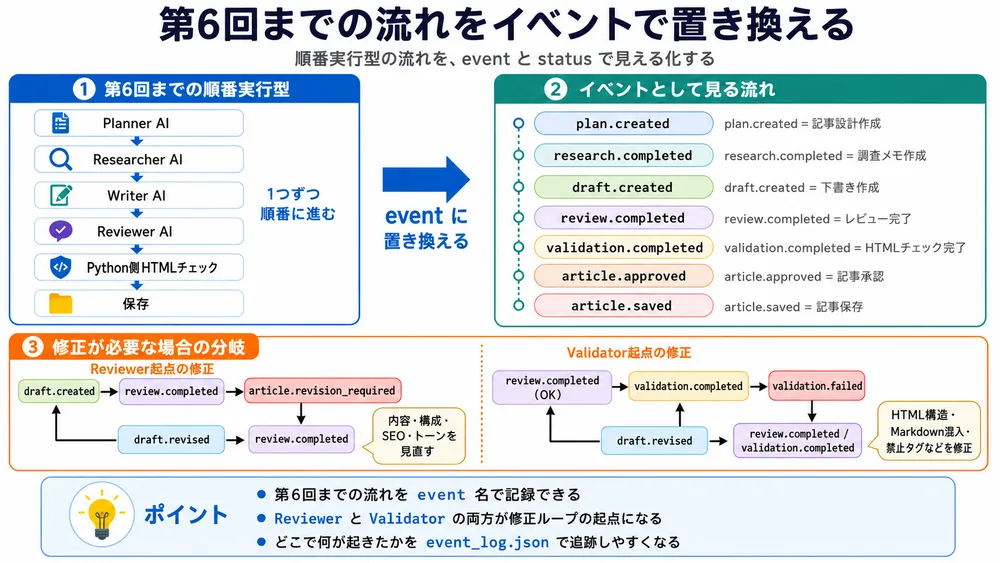
第6回AI記事作成までの流れは、次のような順番実行型でした。
1. Planner AIが記事設計を作る
2. Researcher AIが調査メモを作る
3. Writer AIが記事を書く
4. Reviewer AIがレビューする
5. Python側HTMLチェックをする
6. OKなら保存する第7回AI記事作成では、これをイベントとして実行します。
plan.created
↓
research.completed
↓
draft.created
↓
review.completed
↓
validation.completed
↓
article.approved
↓
article.saved修正が必要な場合は、次のようになります。
draft.created
↓
review.completed
↓
article.revision_required
↓
draft.revised
↓
review.completed
↓
validation.completed
↓
article.approved
↓
article.savedValidatorで問題が出た場合は、次の流れです。
review.completed
↓
status = OK
↓
validation.completed
↓
validation.failed
↓
draft.revised
↓
review.completed
↓
validation.completed
↓
article.approved
↓
article.savedこのようにイベントとして整理すると、記事作成の流れを「状態遷移」として追跡できます。
第7回AI記事作成 ファイル構成と追加・変更ファイル
第7回AI記事作成のファイル構成
article-agent/
├ main.py ← 変更
├ llm_client.py
├ validators.py
├ review_parser.py
├ event_types.py ← 追加
├ event_bus.py ← 追加
├ agents/
│ ├ planner.py
│ ├ researcher.pyy ← 変更(バグ修正)
│ ├ writer.py
│ └ reviewer.py
├ mcp_client.py
├ mcp_server.py
├ web_search_tool.py
└ output/
└ 2026xxxx_xxxxxx_キーワード/
├ plan.txt
├ research_query.txt
├ web_search_results.json
├ research_note.txt
├ draft_1.html
├ review_1.txt
├ review_result_1.json
├ validation_1.txt
├ event_log.json ← 追加保存
├ final_article.html
└ run_summary.txt第7回AI記事作成で追加するファイル
event_types.py
イベント名をまとめるためのファイルです。
役割:
・イベント名を定数として管理する
・plan.created などの文字列のタイプミスを防ぐ
・main.py からイベント名を呼び出しやすくする主なイベント名は以下です。
PLAN_CREATED
RESEARCH_COMPLETED
DRAFT_CREATED
DRAFT_REVISED
REVIEW_COMPLETED
ARTICLE_REVISION_REQUIRED
VALIDATION_COMPLETED
VALIDATION_FAILED
ARTICLE_APPROVED
ARTICLE_SAVEDevent_types.py
イベント名を定義するファイル。
"""
第7回:イベント駆動型マルチエージェント用のイベント定義。
イベント名を定数としてまとめておくことで、
main.py 内での文字列のタイプミスを防ぎやすくする。
"""
# Planner AI
PLAN_CREATED = "plan.created"
# Researcher AI
RESEARCH_COMPLETED = "research.completed"
# Writer AI
DRAFT_CREATED = "draft.created"
DRAFT_REVISED = "draft.revised"
# Reviewer AI
REVIEW_COMPLETED = "review.completed"
ARTICLE_REVISION_REQUIRED = "article.revision_required"
# Validator / Python側HTMLチェック
VALIDATION_COMPLETED = "validation.completed"
VALIDATION_FAILED = "validation.failed"
# Approval / Save
ARTICLE_APPROVED = "article.approved"
ARTICLE_SAVED = "article.saved"
# Error / Unknown
REVIEW_UNKNOWN = "review.unknown"
PROCESS_FAILED = "process.failed"event_bus.py
イベントを記録するためのファイルです。
役割:
・処理の節目で event を発行する
・event / status / payload を記録する
・最後に event_log.json として保存できる形にする第7回AI記事作成では、正式なイベントキューや非同期処理をつくりません。
event_bus.pyをイベント履歴を記録する簡易EventBus として使います。
event_bus.py
イベントを記録するファイル。
from datetime import datetime
import json
class EventBus:
"""
第7回:簡易EventBus。
本格的なイベントキューや非同期処理ではなく、
処理の節目で event / status / payload を記録するための仕組み。
第7回では、このイベント履歴を event_log.json として保存する。
"""
def __init__(self):
self.events = []
def emit(
self,
event: str,
status: str = "OK",
payload: dict | None = None,
) -> dict:
"""
イベントを発行して、イベント履歴に追加する。
Parameters
----------
event : str
plan.created / review.completed などのイベント名。
status : str
OK / REVISION_REQUIRED / FAILED / UNKNOWN などの状態。
payload : dict | None
イベントに付随するデータ。
例:保存先パス、レビュー回数、指摘内容など。
Returns
-------
dict
記録されたイベントデータ。
"""
event_record = {
"time": datetime.now().isoformat(timespec="seconds"),
"event": event,
"status": status,
"payload": payload or {},
}
self.events.append(event_record)
return event_record
def to_list(self) -> list[dict]:
"""
イベント履歴をリスト形式で返す。
"""
return self.events
def to_json(self) -> str:
"""
イベント履歴をJSON文字列として返す。
event_log.json に保存するために使う。
"""
return json.dumps(
self.events,
ensure_ascii=False,
indent=2,
)
def clear(self) -> None:
"""
イベント履歴をリセットする。
通常の実行ではあまり使わないが、
テスト時に使える。
"""
self.events.clear()第7回AI記事作成で変更するファイル
main.py
第7回で最も大きく変更するファイルです。
変更内容:
・EventBusを読み込む
・event_types.py のイベント名を読み込む
・Planner完了時に plan.created を記録する
・Researcher完了時に research.completed を記録する
・Writer初稿作成時に draft.created を記録する
・Writer修正時に draft.revised を記録する
・Reviewer完了時に review.completed を記録する
・Reviewerが修正必要なら article.revision_required を記録する
・Validatorチェック完了時に validation.completed を記録する
・Validatorで問題があれば validation.failed を記録する
・記事がOKなら article.approved を記録する
・保存完了時に article.saved を記録する
・event_log.json を保存する第7回では、main.py が ディスパッチャー相当 の役割も持ちます。
event_bus.py
→ イベントを記録する
main.py
→ event / status を見て次の処理を決めるmain.py
第6回AI記事作成の処理に、event_bus.py と event_types.py を追加して、各処理の節目で event_log.json にイベントを記録する構成です。
from datetime import datetime
import re
from agents.planner import run_planner
from agents.researcher import create_research_queries, run_researcher
from agents.writer import run_writer
from agents.reviewer import run_reviewer
from mcp_client import save_text_file, save_article, save_run_summary, web_search
from validators import validate_html_fragment, sanitize_html_fragment
from web_search_tool import web_search_results_to_text, web_search_results_to_json
from review_parser import (
parse_review_result,
review_result_to_text,
build_review_json_feedback,
build_unknown_review_feedback,
)
from event_bus import EventBus
import event_types as events
MAX_REVIEW_LOOPS = 3
MAX_SEARCH_RESULTS_PER_QUERY = 3
def slugify_keyword(keyword: str) -> str:
"""
フォルダ名に使いやすいようにキーワードを簡易変換する。
日本語はそのまま残し、使いにくい記号だけ置き換える。
"""
slug = keyword.strip()
slug = re.sub(r"\s+", "_", slug)
slug = re.sub(r'[\\/:*?"<>|]', "_", slug)
if not slug:
slug = "article"
return slug[:40]
def build_validation_text(issues: list[str]) -> str:
"""
Python側HTMLチェック結果を保存用テキストに変換する。
"""
if not issues:
return "Python側HTMLチェック:OK\n"
lines = [
"Python側HTMLチェック:修正必要",
"",
]
for issue in issues:
lines.append(f"- {issue}")
return "\n".join(lines)
def build_validation_review(issues: list[str]) -> str:
"""
Python側チェックで見つかった問題を、
Writer AIに渡せるレビュー文に変換する。
"""
issue_text = "\n".join(f"- {issue}" for issue in issues)
return f"""
Python側のHTML形式チェックで、以下の問題が見つかりました。
{issue_text}
Writer AIへの修正指示:
・上記の問題をすべて修正してください。
・記事本文の内容は削除せず、維持してください。
・プレースホルダーに置き換えないでください。
・HTML断片として出力してください。
・styleタグ、style属性、CSS、JavaScriptは使わないでください。
・Markdown記法は使わず、HTMLタグに変換してください。
・必ず修正後の記事全文を出力してください。
status:
VALIDATION_FAILED
"""
def save_event_log(run_dir: str, event_bus: EventBus) -> None:
"""
現在までのイベント履歴を event_log.json に保存する。
実行途中でも保存できるように関数化しておく。
"""
save_text_file(
f"{run_dir}/event_log.json",
event_bus.to_json(),
)
def main():
print("Gemma 4ローカル・マルチエージェント記事作成システム")
print("-" * 50)
event_bus = EventBus()
keyword = input("記事キーワードを入力してください: ").strip()
if not keyword:
print("キーワードが入力されていません。終了します。")
event_bus.emit(
events.PROCESS_FAILED,
status="FAILED",
payload={
"reason": "キーワードが入力されていません。",
},
)
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
keyword_slug = slugify_keyword(keyword)
run_dir = f"output/{timestamp}_{keyword_slug}"
print(f"\n実行結果フォルダ: {run_dir}")
event_bus.emit(
"process.started",
status="OK",
payload={
"keyword": keyword,
"run_dir": run_dir,
},
)
print("\n[1] Planner AI が記事設計を作成中...")
plan = run_planner(keyword)
plan_path = f"{run_dir}/plan.txt"
save_text_file(plan_path, plan)
event_bus.emit(
events.PLAN_CREATED,
status="OK",
payload={
"path": plan_path,
},
)
print("\n[2] Researcher AI が検索クエリを作成中...")
research_queries = create_research_queries(keyword=keyword, plan=plan)
research_query_text = "\n".join(f"- {query}" for query in research_queries)
research_query_path = f"{run_dir}/research_query.txt"
save_text_file(research_query_path, research_query_text)
event_bus.emit(
"research.query_created",
status="OK",
payload={
"path": research_query_path,
"queries": research_queries,
},
)
print("\n--- Researcher AI の検索クエリ ---")
print(research_query_text)
print("--- 検索クエリここまで ---")
print("\n[3] Brave Search APIでWeb検索中...")
all_search_results = []
for query in research_queries:
print(f"- 検索中: {query}")
result = web_search(query=query, max_results=MAX_SEARCH_RESULTS_PER_QUERY)
all_search_results.append(result)
event_bus.emit(
"web_search.completed",
status=result.get("status", "UNKNOWN").upper(),
payload={
"query": query,
"provider": result.get("provider", ""),
"result_count": len(result.get("results", [])),
"message": result.get("message", ""),
},
)
search_results_json = web_search_results_to_json(all_search_results)
search_results_text = web_search_results_to_text(all_search_results)
web_search_results_path = f"{run_dir}/web_search_results.json"
save_text_file(web_search_results_path, search_results_json)
event_bus.emit(
"web_search_results.saved",
status="OK",
payload={
"path": web_search_results_path,
},
)
print("\n[4] Researcher AI が調査メモを作成中...")
research_note = run_researcher(
keyword=keyword,
plan=plan,
search_results_text=search_results_text,
)
research_note_path = f"{run_dir}/research_note.txt"
save_text_file(research_note_path, research_note)
event_bus.emit(
events.RESEARCH_COMPLETED,
status="OK",
payload={
"path": research_note_path,
},
)
print("\n--- Researcher AI の調査メモ ---")
print(research_note)
print("--- 調査メモここまで ---")
print("\n[5] Writer AI が初稿を作成中...")
article = run_writer(
keyword=keyword,
plan=plan,
research_note=research_note,
)
article = sanitize_html_fragment(article)
draft_path = f"{run_dir}/draft_1.html"
save_text_file(draft_path, article)
event_bus.emit(
events.DRAFT_CREATED,
status="OK",
payload={
"loop": 0,
"path": draft_path,
},
)
latest_review = ""
latest_review_result = {
"status": "UNKNOWN",
"summary": "まだレビューは実行されていません。",
"issues": [],
"next_action": "RETRY_REVIEW",
}
review_passed = False
final_review_status = "UNKNOWN"
final_validation_issues: list[str] = []
for loop_count in range(1, MAX_REVIEW_LOOPS + 1):
print(f"\n[6] Reviewer AI がレビュー中... ({loop_count}/{MAX_REVIEW_LOOPS})")
latest_review = run_reviewer(keyword=keyword, draft=article)
review_path = f"{run_dir}/review_{loop_count}.txt"
save_text_file(review_path, latest_review)
print("\n--- Reviewer AI のレビュー結果 ---")
print(latest_review)
print("--- レビュー結果ここまで ---")
latest_review_result = parse_review_result(latest_review)
final_review_status = latest_review_result["status"]
review_result_path = f"{run_dir}/review_result_{loop_count}.json"
save_text_file(
review_result_path,
review_result_to_text(latest_review_result),
)
event_bus.emit(
events.REVIEW_COMPLETED,
status=final_review_status,
payload={
"loop": loop_count,
"review_path": review_path,
"review_result_path": review_result_path,
"summary": latest_review_result.get("summary", ""),
"issues": latest_review_result.get("issues", []),
"next_action": latest_review_result.get("next_action", ""),
},
)
print("\n--- Reviewer AI の判定JSON ---")
print(review_result_to_text(latest_review_result))
print("--- 判定JSONここまで ---")
if final_review_status == "UNKNOWN":
print("\nReviewer AI の判定JSONが不明です。修正必要として扱います。")
event_bus.emit(
events.REVIEW_UNKNOWN,
status="UNKNOWN",
payload={
"loop": loop_count,
"reason": "Reviewer AI の判定JSONが不明です。",
},
)
if final_review_status == "REVISION_REQUIRED":
event_bus.emit(
events.ARTICLE_REVISION_REQUIRED,
status="REVISION_REQUIRED",
payload={
"loop": loop_count,
"source": "reviewer",
"issues": latest_review_result.get("issues", []),
},
)
article = sanitize_html_fragment(article)
validation_issues = validate_html_fragment(article)
final_validation_issues = validation_issues
validation_text = build_validation_text(validation_issues)
validation_path = f"{run_dir}/validation_{loop_count}.txt"
save_text_file(validation_path, validation_text)
if validation_issues:
validation_status = "FAILED"
else:
validation_status = "OK"
event_bus.emit(
events.VALIDATION_COMPLETED,
status=validation_status,
payload={
"loop": loop_count,
"path": validation_path,
"issues": validation_issues,
},
)
if validation_issues:
print("\nPython側HTMLチェック:修正必要")
for issue in validation_issues:
print(f"- {issue}")
event_bus.emit(
events.VALIDATION_FAILED,
status="FAILED",
payload={
"loop": loop_count,
"source": "validator",
"issues": validation_issues,
},
)
if final_review_status == "OK" and not validation_issues:
print("\nReviewer AI JSON判定 + Python側HTMLチェック の判定:OK")
event_bus.emit(
events.ARTICLE_APPROVED,
status="OK",
payload={
"loop": loop_count,
"review_status": final_review_status,
"validation_status": validation_status,
},
)
review_passed = True
break
print("\n判定:修正必要")
if loop_count == MAX_REVIEW_LOOPS:
print("\n最大レビュー回数に達しました。これ以上修正せず、最後に検証済みの記事を保存します。")
event_bus.emit(
"review.max_loops_reached",
status="MAX_LOOPS_REACHED",
payload={
"loop": loop_count,
"max_review_loops": MAX_REVIEW_LOOPS,
"review_status": final_review_status,
"validation_issues": validation_issues,
},
)
break
if validation_issues:
review_for_writer = build_validation_review(validation_issues)
revision_source = "validator"
elif final_review_status == "REVISION_REQUIRED":
review_for_writer = build_review_json_feedback(latest_review_result)
revision_source = "reviewer"
else:
review_for_writer = build_unknown_review_feedback(latest_review, latest_review_result)
revision_source = "unknown_review"
print(f"\n[7] Writer AI がレビュー指摘に従って修正中... ({loop_count}/{MAX_REVIEW_LOOPS})")
event_bus.emit(
"writer.revision_requested",
status="REVISION_REQUIRED",
payload={
"loop": loop_count,
"source": revision_source,
},
)
article = run_writer(
keyword=keyword,
plan=plan,
research_note=research_note,
review=review_for_writer,
previous_draft=article,
)
article = sanitize_html_fragment(article)
next_draft_number = loop_count + 1
revised_draft_path = f"{run_dir}/draft_{next_draft_number}.html"
save_text_file(revised_draft_path, article)
event_bus.emit(
events.DRAFT_REVISED,
status="OK",
payload={
"loop": loop_count,
"source": revision_source,
"path": revised_draft_path,
},
)
# 実行途中でもイベントログを残しておく
save_event_log(run_dir, event_bus)
print("\n[8] 最終HTMLを保存中...")
article = sanitize_html_fragment(article)
result = save_article(run_dir, article)
event_bus.emit(
events.ARTICLE_SAVED,
status="OK",
payload={
"path": result["path"],
"review_passed": review_passed,
"final_review_status": final_review_status,
},
)
status_text = "OK判定後に保存" if review_passed else "最大レビュー回数到達後に保存"
if final_validation_issues:
validation_summary = "\n".join(f"- {issue}" for issue in final_validation_issues)
else:
validation_summary = "Python側HTMLチェック:OK"
review_json_summary = review_result_to_text(latest_review_result)
summary = f"""実行キーワード:{keyword}
保存状態:{status_text}
Reviewer最終JSON判定:{final_review_status}
最終保存先:{result['path']}
レビュー最大回数:{MAX_REVIEW_LOOPS}
実行結果フォルダ:{run_dir}
検索クエリ:
{research_query_text}
最終Reviewer判定JSON:
{review_json_summary}
最終Python側HTMLチェック:
{validation_summary}
イベントログ:
{run_dir}/event_log.json
"""
save_run_summary(run_dir, summary)
event_bus.emit(
"process.completed",
status="OK" if review_passed else "COMPLETED_WITH_MAX_LOOPS",
payload={
"keyword": keyword,
"run_dir": run_dir,
"final_article_path": result["path"],
"review_passed": review_passed,
},
)
save_event_log(run_dir, event_bus)
print("\n完了しました。")
print(f"保存先: {result['path']}")
if review_passed:
print("保存状態:Reviewer AI のJSON判定とPython側HTMLチェックのOK後に保存しました。")
else:
print("保存状態:最大レビュー回数に達したため、最後の記事を保存しました。")
print(f"Reviewer最終JSON判定:{final_review_status}")
print(f"イベントログ: {run_dir}/event_log.json")
if __name__ == "__main__":
main()agents/researcher.py
出力が日本語以外になる場合のを修正。
agents/researcher.py
import json
from llm_client import call_gemma4
def _extract_json_array(text: str) -> list[str]:
"""
LLMの出力からJSON配列を取り出す。
失敗した場合は空リストを返す。
"""
text = text.replace("```json", "")
text = text.replace("```JSON", "")
text = text.replace("```", "")
text = text.strip()
first_bracket = text.find("[")
last_bracket = text.rfind("]")
if first_bracket == -1 or last_bracket == -1 or last_bracket <= first_bracket:
return []
json_text = text[first_bracket : last_bracket + 1]
try:
data = json.loads(json_text)
except json.JSONDecodeError:
return []
if not isinstance(data, list):
return []
queries = []
for item in data:
if isinstance(item, str) and item.strip():
queries.append(item.strip())
return queries
def create_research_queries(keyword: str, plan: str) -> list[str]:
"""
Researcher AI:
記事キーワードと記事設計から、Brave Search API用の検索クエリを作成する。
"""
system_prompt = """
あなたは記事作成のためのResearcher AIです。
入力されたキーワードと記事設計をもとに、Web検索に使う検索クエリを作成してください。
重要:
・出力は必ず日本語で行ってください。
・韓国語、英語、中国語など、日本語以外では出力しないでください。
・検索クエリは3〜5個にしてください。
・入力キーワードに年が含まれる場合、その年を優先して検索クエリに含めてください。
・入力キーワードに含まれる年を勝手に変更しないでください。
・最新情報が必要な場合は「最新」「公式」「発表」「比較」「動向」などを含めてください。
・信頼性の高い情報を探しやすいクエリにしてください。
・検索APIに渡しやすい短めの検索語にしてください。
・出力はJSON配列のみとしてください。
・コードブロック記号は使わないでください。
"""
user_prompt = f"""
以下のキーワードと記事設計をもとに、Web検索用クエリをJSON配列で作成してください。
必ず守る条件:
・出力はJSON配列のみです。
・配列内の検索クエリは日本語で作成してください。
・韓国語、英語、中国語など、日本語以外を使わないでください。
・入力キーワード「{keyword}」の主題を変更しないでください。
・入力キーワードに含まれる年を変更しないでください。
・キーワードに「2026年」が含まれる場合、「2024年」「2025年」を主軸にした検索クエリにしないでください。
キーワード:
{keyword}
記事設計:
{plan}
条件:
・「最新AIモデル」が主題の場合、AIモデル名、基盤モデル、LLM、マルチモーダル、AIエージェントなどを調べやすい検索クエリにしてください。
・公式発表や信頼性の高い情報源に近づける検索クエリを含めてください。
出力例:
[
"2026年 最新AIモデル 比較",
"2026年 基盤モデル LLM 最新動向",
"マルチモーダルAI AIエージェント 最新モデル"
]
"""
response = call_gemma4(system_prompt, user_prompt)
queries = _extract_json_array(response)
if queries:
return queries[:5]
# LLM出力が崩れた場合のフォールバック
return [
f"{keyword} 最新",
f"{keyword} 公式",
f"{keyword} 比較",
]
def run_researcher(keyword: str, plan: str, search_results_text: str) -> str:
"""
Researcher AI:
Brave Search APIの検索結果をもとに、Writer AIへ渡す調査メモを作成する。
"""
system_prompt = """
あなたは記事作成のためのResearcher AIです。
Web検索結果を読み、Writer AIが記事作成に使いやすい調査メモを作成してください。
最重要ルール:
・出力は必ず日本語で行ってください。
・韓国語、英語、中国語など、日本語以外では絶対に出力しないでください。
・見出し、本文、箇条書き、表のすべてを日本語で書いてください。
・入力キーワードに含まれる年や主題を勝手に変更しないでください。
・キーワードが「2026年」を含む場合、2024年や2025年の記事として扱わないでください。
・調査メモのタイトルにも、入力キーワードの主題を反映してください。
・検索結果の title / URL / 概要 を必ず根拠として使ってください。
・参考URL一覧を必ず作成してください。
・検索結果にURLがある場合、最低3件以上のURLを列挙してください。
・検索結果にない事実、モデル名、数値、リリース情報を断定しないでください。
・不確かな情報は「検索結果だけでは確認できない」と明記してください。
・検索結果をそのまま貼り付けるのではなく、記事で使える調査メモに整理してください。
・単なる一般的な記事企画書や構成案だけで終わらせないでください。
調査メモの目的:
・Writer AIが、検索結果に基づいて日本語の記事を書けるようにすること。
・一般論ではなく、検索結果から確認できた論点を渡すこと。
・検索結果に含まれる情報と、推測や補足を明確に分けること。
・Writer AIが入力キーワードから外れた記事を書かないように、主題と年を固定すること。
"""
user_prompt = f"""
以下のキーワード、記事設計、Web検索結果をもとに、Writer AIへ渡す調査メモを作成してください。
必ず守る条件:
・出力はすべて日本語にしてください。
・韓国語、英語、中国語など、日本語以外で出力しないでください。
・入力キーワード「{keyword}」を変更しないでください。
・入力キーワードに含まれる年を変更しないでください。
・キーワードが「2026年」を含む場合、2024年や2025年の記事として扱わないでください。
・調査メモのタイトルにも、入力キーワードの主題を反映してください。
・検索結果のURLを参考URL一覧に必ず残してください。
・検索結果にURLが1件でもある場合、参考URL一覧を省略しないでください。
・検索結果にない情報は断定せず、「検索結果だけでは確認できない」と書いてください。
・一般的な記事企画書ではなく、Writer AIが記事本文に使える根拠付きの調査メモにしてください。
キーワード:
{keyword}
記事設計:
{plan}
Web検索結果:
{search_results_text}
出力形式:
# 調査メモ:{keyword}
## 1. 検索結果から確認できた事実
検索結果の title / URL / 概要 をもとに、確認できた事実を箇条書きで整理してください。
各項目には、できるだけ参照元URLを添えてください。
## 2. 記事に反映すべき重要ポイント
Writer AIが記事本文に反映すべきポイントを整理してください。
入力キーワードから外れた内容に広げすぎないでください。
入力キーワードに含まれる年を必ず守ってください。
## 3. 参考URL一覧
検索結果に含まれるURLを最低3件以上列挙してください。
URLがある場合は必ずそのまま出力してください。
URLが3件未満の場合は、取得できたURLをすべて出力してください。
## 4. 検索結果だけでは不足している点
検索結果だけでは確認できないこと、断定してはいけないことを整理してください。
## 5. Writer AIへの具体的な指示
Writer AIが記事を書くときの注意点を整理してください。
必ず以下を含めてください。
・記事タイトルには入力キーワードを自然に含める
・入力キーワードに含まれる年を変更しない
・キーワードが2026年を含む場合、2024年や2025年の記事にしない
・検索結果に出てきた主要論点を反映する
・検索結果にない最新情報やモデル名を断定しない
・出典URLを参考リンクとして記事内または記事末尾に残す
禁止事項:
・日本語以外で出力すること
・韓国語で出力すること
・英語だけで出力すること
・検索結果にURLがあるのに、参考URL一覧を省略すること
・入力キーワードが2026年なのに、2024年や2025年の記事として扱うこと
・検索結果にない具体的なモデル名や数値を断定すること
・単なる一般論だけの構成案にすること
"""
return call_gemma4(system_prompt, user_prompt)第7回AI記事作成で追加される出力ファイル
第7回では、実行結果フォルダに以下が追加されます。
event_log.json第7回AI記事作成の実行結果
ターミナル出力
(UTF-8)
(SHIFT-JIS)
出力記事
(UTF-8)
(SHIFT-JIS)
event_log.json
(UTF-8)
(SHIFT-JIS)
イベント駆動型マルチエージェント実装範囲
第7回のイベント駆動型マルチエージェントでは、正式なDispatcherや非同期イベントキューまで実装しません。
第7回のイベント駆動型マルチエージェントでの実装範囲は以下の様になります。
実装する機能:
・イベント名を定義する
・イベントを記録する
・event_log.json に保存する
・main.py の分岐をディスパッチャー相当として扱う
実装しない機能:
・dispatcher.py の分離
・本格的なEvent Queue
・非同期処理
・ワーカー実行
・リトライ制御つまり、第7回の追加・変更は最小限で、イベント駆動型の考え方を現在のマルチエージェント記事作成システムに導入する回です。
まとめ:イベント化するとAIエージェントの流れが見える
第7回AI記事作成では、これまで順番に実行していたAI記事作成フローを、イベント駆動型の考え方で整理しました。
第5回でReviewer AIの判定をJSON化し、第6回でResearcher AIとWeb検索MCP風ツールを追加しました。
第7回では、その結果を event と status で扱います。
Reviewer AIがOK
↓
review.completed
↓
validation.completed
Reviewer AIが修正必要
↓
article.revision_required
↓
Writer AIへ戻す
Validatorが問題を検出
↓
validation.failed
↓
Writer AIへ戻すこのように、処理の節目をイベントとして記録することで、どこで何が起きたかを追いやすくなります。
第7回は、ローカルAIマルチエージェント記事作成システムを、状態を持つエージェントシステムへ変更する回でした。
今回のイベント駆動型では、ディスパッチャー部分は main.py 内の status 判定と分岐処理になります。
今後、本格的にイベント駆動型にする場合は、ディスパッチャー部分をmain.pyから分離してDispatcherでイベント振り分けをする必要があります。
Dispatcherを実装したイベント駆動型マルチエージェント