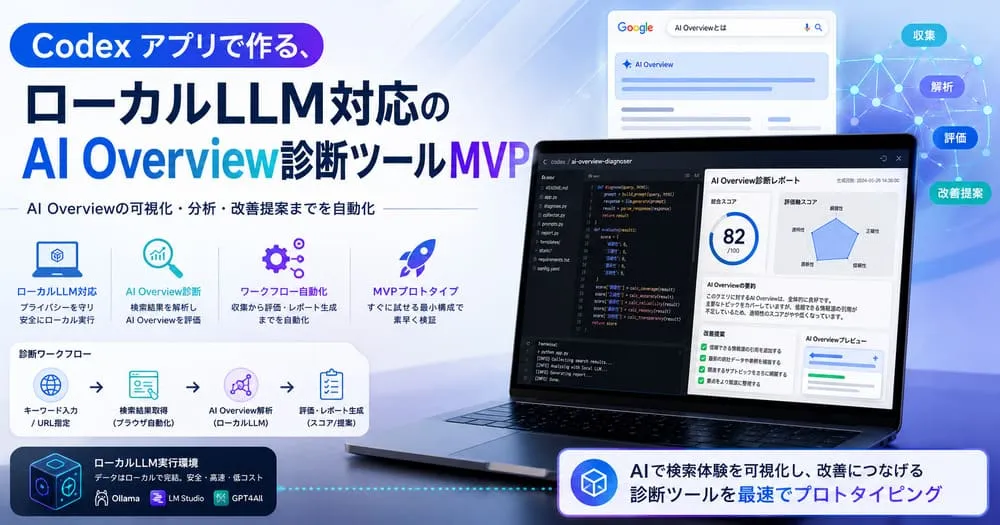
Codex アプリを使って、AI OverviewやAI検索に引用されやすい記事構造になっているかを、自分のローカル環境で確認できる診断ツールを作りました。
特徴は、OpenAI APIを使わないことです。
LLM部分はOllamaでローカル実行し、スコア計算はルールベースで安定して出す構成にしています。
この記事では、Next.js App Router、TypeScript、Tailwind CSS、Ollamaを使って、本文入力とURL診断に対応した「AI Overview診断ツール」のMVPを作った流れをまとめます。
Codex アプリで作ったもの
今回作ったのは、記事本文または記事URLを入力すると、AI OverviewやAI検索に引用されやすい構造になっているかを診断するWebアプリです。
- 記事本文を直接貼り付けて診断
- URLを指定してページ本文を取得して診断
- ルールベースで100点満点のスコアを算出
- Ollamaで改善提案を生成
- FAQ案を5個生成
- メタディスクリプション案を3個生成
- Ollamaが失敗しても、ルールベース診断だけは表示
自分用MVPなので、ログイン機能やDBは入れていません。ローカル環境で動けばよい、という前提となっています。
作業手順
作業フォルダ(AI-Overview)を新規作成し、作成したフォルダをCodex アプリのプロジェクトフォルダとした後に、チャット欄に下記に添付したプロンプトを入力し送信します。
UTF-8
Shift-JIS
Codex アプリ設定
- 権限:デフォルト権限
- インテリジェンス(推論の強さ):中
- 使用モデル:GPT5.5
- 速度:標準
AI Overview診断ツール起動画面
Codex アプリが作成したREADMEに従い、LLM(ollama+qwen3)と開発サーバー起動(npm run dev)後に、http://localhost:3000/にアクセスすると下記の画面が表示されます。
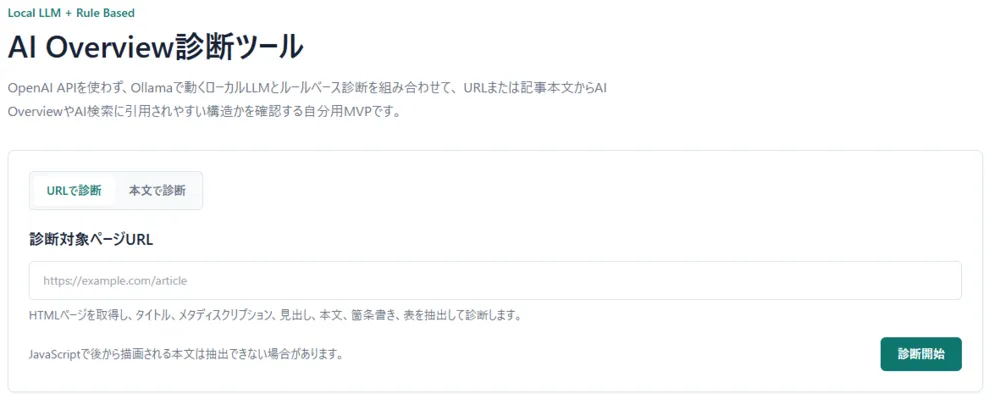
診断対象のURLまたは本文入力後に、診断開始をクリックすると下記の診断結果が表示されます。

Codex アプリ実行内容
以下は、プロンプトの指示によりCodex アプリが自律的に考えて実行した内容です。
技術構成
- Next.js App Router
- TypeScript
- React
- Tailwind CSS
- Ollama API
- DBなし
- 認証なし
- OpenAI APIなし
Ollama APIのエンドポイントは次の形です。
http://localhost:11434/api/generate使用するモデル名は、環境変数から読み込むようにしました。
OLLAMA_MODEL=qwen3:latest
OLLAMA_ENDPOINT=http://localhost:11434/api/generate診断は2段階に分けた
今回の診断は、次の2段階に分けています。
- ルールベース診断
- ローカルLLMによる改善提案
ポイントは、総合スコアをLLMに決めさせないことです。
LLMは便利ですが、同じ本文でも出力が揺れることがあります。そのため、スコアはプログラムで安定して計算し、LLMには改善提案やFAQ案の生成だけを任せる設計にしました。
ルールベース診断で見ている項目
ルールベース診断では、以下の10項目をそれぞれ0〜10点で評価し、合計を100点満点に換算しています。
- 本文文字数
- 見出し数
- 質問型見出しの有無
- 冒頭に結論があるか
- 箇条書きの有無
- 表の有無
- FAQの有無
- 根拠・一次情報の有無
- E-E-A-T要素の有無
- 構造化データにしやすい要素の有無
たとえば、本文文字数は次のように評価しています。
- 1,000文字未満:低評価
- 1,000〜3,000文字:中評価
- 3,000文字以上:高評価
見出しについては、Markdownの「#」「##」「###」や、HTMLの「h2」「h3」を検出します。
質問型見出しでは、「とは」「なぜ」「方法」「どう」「いつ」「どこ」「いくら」「できますか」「必要か」などの語句を見ています。
AI Overviewを意識した構造チェック
AI OverviewやAI検索に引用されやすい記事は、単に長文であればよいわけではありません。
検索意図に対して、答えが分かりやすく整理されていることが重要です。
そのため、今回の診断では以下のような要素を重視しました。
- 冒頭で結論を示しているか
- 見出しごとに論点が分かれているか
- 質問に対する答えが明確か
- 箇条書きで要点を整理しているか
- 比較情報を表で整理しているか
- FAQ形式で補足しているか
- 公式情報、出典、データ、調査などの根拠があるか
- 実績、事例、経験、監修などのE-E-A-T要素があるか
Ollamaで改善提案を生成する
ルールベース診断が終わったら、診断結果と記事本文をOllamaに渡します。
Ollamaには、以下の内容をJSON形式で返すように指示しました。
- 評価サマリー
- 改善すべき点
- 具体的な改善提案
- FAQ案5個
- メタディスクリプション案3個
返却形式は次のように固定しています。
{
"summary": "string",
"problems": ["string"],
"improvements": ["string"],
"faqIdeas": [
{
"question": "string",
"answer": "string"
}
],
"metaDescriptions": ["string"]
}重要なのは、LLMのJSON出力が崩れてもアプリ全体を落とさないことです。
JSONのパースに失敗した場合でも、ルールベース診断結果だけは返すようにしました。
Ollama連携で詰まった点
実装中に一度、画面上で「Ollamaまたはモデル設定を確認してください」と表示されました。
確認してみると、Ollama自体は起動しており、モデルも存在していました。原因は、初回のモデルロードと生成に時間がかかり、API側のタイムアウトを超えていたことでした。
そこで、次のように改善しました。
- タイムアウトを60秒から180秒に延長
- Ollama APIに
format: "json"を指定 temperatureを低めに設定num_predictで出力長を制御- フォールバック時に実際の失敗理由を表示
これにより、Ollamaの応答が安定し、llmStatus: "success" が返るようになりました。
URL診断にも対応した
最初は本文入力だけに対応していましたが、途中でURL指定でも診断できるように変更しました。
URL診断では、指定されたページのHTMLを取得し、以下の要素を抽出しています。
- title
- meta description
- h1
- h2
- h3
- li
- table
- 本文テキスト
抽出したHTML要素は、診断しやすいようにMarkdown風のテキストへ変換してから、既存のルールベース診断に渡しています。
これにより、本文を手動で貼り付けなくても、URLだけで診断できるようになりました。
URL診断の注意点
URL診断には限界もあります。
今回のMVPでは、通常のHTMLを取得して本文を抽出しています。そのため、以下のようなページではうまく本文を取得できない場合があります。
- JavaScriptで後から本文を描画するページ
- ログインが必要なページ
- 本文がほとんどHTMLに含まれていないページ
- PDFや画像ファイル
- HTML構造が特殊なページ
その場合は、本文入力モードに切り替えて、記事本文を直接貼り付けて診断する運用にしています。
画面の構成
画面はシンプルにしました。
- アプリタイトル
- 説明文
- URL入力と本文入力の切り替え
- 診断開始ボタン
- 総合スコア
- 評価サマリー
- 項目別スコア表
- 改善すべき点
- 具体的な改善提案
- FAQ案
- メタディスクリプション案
Tailwind CSSを使い、白背景、カード形式、表形式のスコア表示にしています。
自分用MVPなので、派手なUIよりも、診断結果を読みやすいことを優先しました。
セットアップ手順
まず、Ollamaをインストールします。
公式サイトはこちらです。
https://ollama.com/次に、使用するモデルを取得します。
ollama pull qwen3:latestOllamaが起動しているか確認します。
ollama listcurl http://localhost:11434/api/tagsアプリ側では依存関係をインストールします。
npm install.env.local を作成します。
OLLAMA_MODEL=qwen3:latest
OLLAMA_ENDPOINT=http://localhost:11434/api/generate開発サーバーを起動します。
npm run devブラウザで以下を開きます。
http://localhost:3000よくあるエラー
Ollamaに接続できない
Ollamaが起動していない可能性があります。
curl http://localhost:11434/api/tagsこのコマンドで応答が返るか確認します。
モデルが見つからない
.env.local の OLLAMA_MODEL と、実際に取得済みのモデル名が一致していない可能性があります。
ollama list必要であれば、モデルを取得します。
ollama pull qwen3:latestLLMのJSON出力が崩れる
Ollamaのモデルが、指示どおりにJSONだけを返さない場合があります。
この場合でも、ルールベース診断結果は表示されるようにしています。
URLから本文を抽出できない
JavaScript描画のページやログインが必要なページでは、本文を取得できない場合があります。
その場合は、本文入力モードで記事本文を直接貼り付けます。
今回の実装で重視したこと
今回のMVPでは、完璧なAI診断よりも、ローカル環境で安定して動くことを重視しました。
特に意識したのは次の点です。
- OpenAI APIを使わない
- スコアはLLMではなくルールベースで決める
- LLMが失敗してもアプリ全体を落とさない
- エラー内容を日本語で分かりやすく表示する
- URL診断と本文診断の両方に対応する
- 自分用MVPとしてすぐ使える形にする
今後の改善案
今後改善するなら、以下のような機能を追加したいです。
- Playwrightを使ってJavaScript描画ページも診断する
- 診断履歴を保存する
- 記事ジャンルごとにスコアの重みを変える
- FAQ構造化データのJSON-LD案を生成する
- 競合ページとの比較診断を行う
- 利用するOllamaモデルを画面で選べるようにする
- 改善後の記事構成案を自動生成する
まとめ
Codex アプリを使って、プロンプトの指示だけで、ローカル環境でLLM(ollama+qwen3)を使って動くAI Overview診断ツールを作ることができました。

作業指示後は、ペットを表示させCodex アプリの進捗状況を確認しながら、他の作業を同時に行いました。
AI OverviewやAI検索を意識した記事改善では、本文の長さだけでなく、見出し、結論、FAQ、表、根拠、E-E-A-T要素などを整理することが重要です。
今回作ったツールは、その構造チェックをローカル環境で手軽に行うための第一歩として使えます。
関連記事